










連載
Radeon R9 290シリーズ「Hawaii」のアーキテクチャを丸裸にする
 |
北米時間2013年9月25日に発表された新しいRadeonファミリーにおける真打ち,Radeon R9 290シリーズの情報がついに解禁となった。
開発コードネームは「Hawaii」(ハワイ)。AMDによると,今回のHawaiiは,Southern Islandsの後継となる「Volcanic Islands」(ヴォルケイニックアイランド,火山島群)に属する製品シリーズということになる。ここでは,AMDのシニアフェローであるMicheal Mantor(マイケル・マンタ―)氏が明らかにしたアーキテクチャの詳細をチェックしていくことにしよう。
Radeon R9 290シリーズの正体
〜GCNをベースに規模を拡大し,各所をリファイン
 |
「Radeon HD 7970」(以下,HD 7970)のトランジスタ数は約43億個だったので,およそ44%も増量した計算だ。
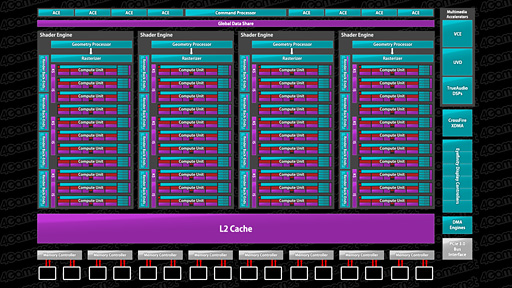
そのブロック図は下に示したとおりだが,GPUの巨大化に合わせて「Shader Engine」(シェーダエンジン)という概念が新たに導入されてきた。これは従来のGCNアーキテクチャ採用GPUにはなかったものだ。
 |
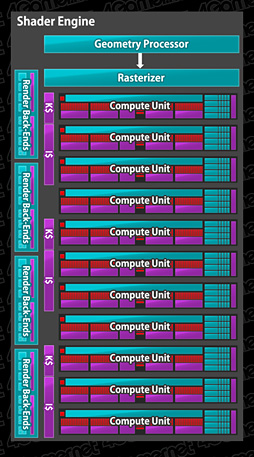 |
また,Shader Engine内には,11基の「Compute Unit」(コンピュートユニット)が用意され,各Compute Unitは,Geometry Processorからジオメトリ系処理,Rasterizerからはピクセル単位処理の発注をそれぞれ受けることになる。
こうして見ると,1基のShader Engineは,それだけでほぼ完結したGPUコアになっていると分かる。レイアウトこそ異なるものの,NVIDIAの「Kepler」および「Fermi」アーキテクチャにおける「Graphics Processing Cluster」(グラフィックスプロセッシングクラスター,GPC)と,構成はそっくりだ。「性能や効率を突き詰めると,デザインは似ていく」という,エンジニアリングの典型を目の当たりにしていると述べてもいいかもしれない。
 |
 |
各Compute Unitは,シェーダプロセッサ「Stream Processor」(ストリームプロセッサ)を16基ひとまとめにした実行ユニットを4つ搭載する。つまり,Compute UnitあたりのStream Processor数は64基ということだ。ちなみにこの「1 Compute Unit=64 Stream Processor」というのは,GCNアーキテクチャを採用するRadeonで一貫した仕様である。
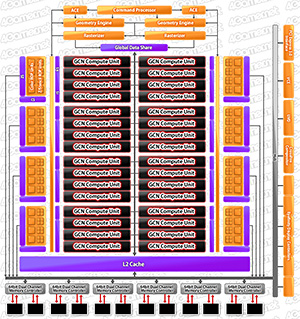 |
HD 7970のブロック図でShader Engineは描かれていないが,なんとなく想像できるように,HD 7970は,16基のCompute Unitからなる“Shader Engine的なもの”2基で構成したものなのだ。実際,HD 7970において,2基ずつ用意されるGeometry EngineやRasterizerはそれぞれ,16基のCompute Unitに対してしか処理を発注できない仕様になっていた。
以上を踏まえて,Radeon R9 290シリーズの上位モデルである「Radeon R9 290X」(以下,R9 290X)とHD 7970を比較したものが表1である。
| R9 290X | HD 7970 | |
|---|---|---|
| Shader Engine数 | 4基 | 2基 |
| Shader EngineあたりのCompute Unit数 | 11基 | 16基 |
| Compute UnitあたりのStream Processor数 | 64基 | 64基 |
| 総Stream Processor数 | 2816基 | 2048基 |
ちなみにRadeon R9 290シリーズの下位モデルであるR9 290“無印”の総Stream Processor数は2560基と発表されているのだが,その内訳は明らかになっていない。可能性として考えられるのは,
- フルスペック版Shader Engineが3基と7 Compute Unit構成のShader Engineが1基
3(Shader Engine) × 11 (Compute Unit) × 64 (Stream Processor) + 1 (Shader Engine)×7 (Compute Unit) × 64 (Stream Processor) = 2560 - 10 Compute Unit構成のShader Engineが4基
4(Shader Engine) × 10 (Compute Unit) × 64 (Stream Processor) = 2560
 |
ちなみにMantor氏は「今回のアーキテクチャにおいて,Shader Engineの数は1〜4基,そしてShader Engine内のCUは1〜11基を柔軟にサポートする」と発言していた。Volcanic Islands世代では今後,そういった下位モデル展開があり得るのかもしれない。
マイナーチェンジこそ入ったものの
Compute Unitの基本構成に変更はない
Compute Unitのブロック図を下に示したが,この基本構造はHD 7970から変わっていないという理解でいい。
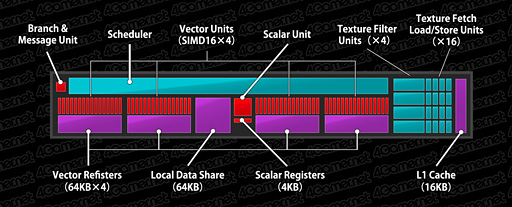 |
図中,16基で一塊となっている赤いブロックはStream Processorだ。1つ1つのStream Processorは32bit単精度浮動小数点演算に対応したスカラユニットで,16基集まることによって,SIMD16(16要素ベクトルの演算)ユニットを構成している。64bit倍精度浮動小数点演算の場合は,2回に分け,2クロックで処理できるが,倍精度の乗算や積和算だとさらに2クロックを要する。
中央にある大きめの赤いブロックは整数演算や論理演算専用ユニット。左上の小さな赤いブロックは分岐命令実行ユニットだ。
Compute Unit内には4基のSIMD16ユニットがあるわけだが,これは,AMD製GPUの演算実行単位である「Wavefront」を同時に4つ実行できることと同義だ。もっとも,Wavefrontは64個のデータからなるスレッド――もしくは「64要素ベクトル」と言ってもいいだろう――なので,SIMD16ユニットはこれを4回に分けて実行することになる。言い換えると,4クロックかけて1 Wavefrontを処理する。繰り返すが,このアーキテクチャはSouthern Islands世代から変わっていない。
では,変更点はないのかというと,あるにはある。
1つは,アドレッシングに(デバイス)フラットアドレッシングがサポートされた点だ(※アドレスレジスタの有効ビット数は64bitだと思われるが,その情報は未公開。確認中なので,明らかになったら追記したい)。
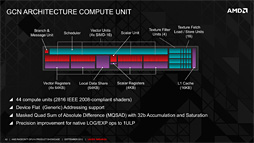 |
MQSAD(Masked Quad Sum of Absolute Difference,マスク対応4要素絶対値差分総和)命令の搭載,そして「対数/指数計算の丸め誤差」の1ULP(1 Unit in the Last Place)までの改善も,Radeon R9 290シリーズのSPへの改善点として挙げられている。
MQSADというのは,「与えた検索キーベクトルと検索対象領域との差分スコア」を出してくれる演算で,認識処理や映像圧縮,動き検出,あるいは動き予測に有効だ。類似の命令はCPUのSSEなどにも搭載されており,いわゆるメディアプロセッシング演算の典型命令といえる。
一方,対数/指数計算の丸め誤差改善は,GPUによるHPC用途(=スーパーコンピュータ用途)に有効なものとなる。
Geometry Processorの改良によってジオメトリシェーダとテッセレーションステージの性能が向上
フロントエンドの「Command Processor」(コマンドプロセッサ)と,頂点単位の処理を司るGeometry Processor部を拡大したものが下のスライドだ。ここではShader Engineが大胆に省略表記されている点に注意したい。
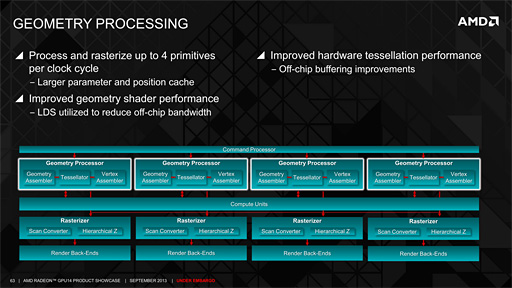 |
ここでのポイントは,Geometry ProcessorがHD 7970の2基に対してRadeon R9 290シリーズでは4基に倍増している点になるだろうが,GCNアーキテクチャにおいては,Shader Engineの数に合わせてGeometry Engineも搭載される仕様なので,これ自体は驚くには値しない。
むしろ重要なのは,Mantor氏が,Radeon R9 290シリーズのGeometry Processorで,性能向上のために手が入っていると述べていることのほうだ。氏によれば,頂点データが増加する処理系であるジオメトリシェーダとテッセレーションステージの実行に関連したチューニングが施されているという。
具体的には,Compute Unit内に実装されている64KBのオンチップ高速メモリたる「Local Data Share」(ローカルデータシェア)を積極的に活用することで,ジオメトリシェーダやテッセレーションステージを介して増加した頂点情報が,相対的に遅いグラフィックスメモリ側へ“吐き出される”のを防ぐような制御を組み込んだとのことだ。
Render Back-Endsは16基,メモリインタフェースは512bitに。メモリバス帯域幅は300GB/s超の世界へ
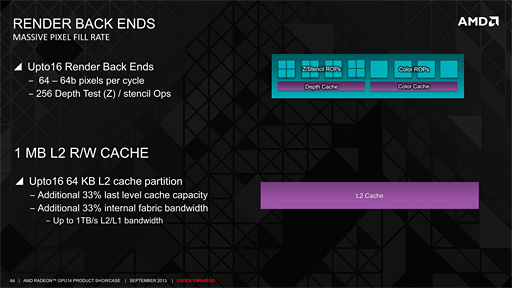
Radeon R9 290シリーズにおいて,Render Back-Endsは最大16基搭載される。前述したとおり,Shader Engineあたり4基のRender Back-Endsを備えるので,Shader Engineが4基で合計16基という計算だ。
Radeon R9 290シリーズのROP(Rendering Output Pipeline,レンダリングアウトプットパイプライン)は,たとえば,αRGBが各16bitで表現されるピクセルのような64bit長のピクセルを1クロックで4つ出力する能力がある。
下に示したスライドでは,Render Back-Endsの拡大図において,「Color ROPs」という文字が4個のマスにかかっているが,この4マス1つ1つがいま説明した能力を持つと考えればいい。GPU全体では,1クロックで64bit長のピクセルを,
- 4(Shader Engine)×4(Render Back-Ends)×4(ピクセル)=64ピクセル
出力できるわけだ。
Zバッファ処理/ステンシル処理も同じで,図中に16基ある「Z/Stencil ROPs」が処理を担当するため,GPU全体では256個(4×4×16=256)の処理を1クロックで行うことができる。
なお,L2キャッシュメモリは,Render Back-Endsあたり64KBのL2キャッシュパーティションが割り当てられている。GPU全体の抱えるRender Back-Ends数は16基なので,GPU全体のL2キャッシュ容量は64×16=1024という計算式で1MBになる。
ちなみにL1およびL2キャッシュの内部帯域幅は1TB/sに達しているとのことだ。
 |
続いてメモリ周りを見ていこう。
Radeon R9 290シリーズと組み合わされるグラフィックスメモリは,データレート5GbpsのGDDR5となる。
メモリバス幅はHD 7970の384bitに対し,Radeon R9 290シリーズでは512bitへと拡張された。GTX TITANでも384bitだったので,GDDR5時代における512bitメモリバス幅はRadeon R9 290シリーズが一番乗りになったわけだ(※GDDR3&4時代だと,「ATI Radeon HD 2900 XT」や「GeForce GTX 280」が512bitインタフェースを採用していた)。
5GbpsデータレートのGDDR5メモリとメモリバス幅512bitにより,Radeon R9 290シリーズのメモリバス帯域幅は320GB/sに到達。Mantor氏によれば,このスペックは「4K(=3840×2160ドット)解像度で60fpsレンダリングするのに必要なもの」とのことだ。
製造プロセスルールが先代と変わらず28nmに留まり,一方でメモリバス幅が384bitから512bitへと拡張したことで,プロセッサ全体におけるメモリインタフェースの面積占有率はかなり上がってしまいそうな印象もあるが,実際には,HD 7970の384bitインタフェース比で20%もコンパクトにまとまったという。これは「物理設計最適化の成果と,384bitインタフェースの(64bit×6という)『3の倍数』のクロスバースイッチよりも,(64bit×8となる)『8の倍数』のクロスバースイッチのほうが設計しやすかったことが影響している」(Mantor氏)からとのこと。
HD 7970比4倍。8基となった
Asynchronus Compute Engine
Radeon R9 290シリーズの全体ブロック図を見ると,最上段に「ACE」というブロックが8つあるが,これは「Asynchronus Compute Engine」の略。一言でまとめると,GPGPU(Compute Shader)のタスクを発注する機能ブロックとなる。
HD 7970で2基しかなかったACEは,Radeon R9 290シリーズで4倍に拡張されたわけだが,これは,活用事例が多方面に広がりを見せるGPGPUに向けた性能向上を狙ったものにほかならない。ちなみに,ACE×8という構成は,PlayStation 4のAPUに統合されたGPUコアでも採用された仕様となる。
このACEを拡大したものが下のスライドだ。
8基あるACEからは異なるGPGPUカーネルを発行して処理させられるようになっており,それぞれを完全並列に動作させることも可能だ。最近では,Unreal Engine 4や,「Frostbite 2」「Frostbite 3」など,グラフィックス描画にあえてGPGPUを用いるゲームエンジンが増えてきているが,今回8基ものACEを実装してきたのは,そうした活用方法にも対応するためなのだろう。
8基あるACEは,それぞれがGPGPUタスク8個分のタスクをキューイングできるようになっており,実行中のGPGPUタスクがメモリアクセスなどによって待機状態になったときには,別のGPGPUタスクに素早く切り換えて実行に移せる。この高速なコンテクストスイッチングを行うため,関連データを「Global Data Share」(グローバルデータシェア)やL2キャッシュに退避できるメカニズムが実装されている。
関連データの退避がGPU内に収まらないときにはグラフィックスメモリへの退避を自動的に請け負う「DMA」(Direct Memory Access)が実装されているのも,スライドからは見て取れよう。
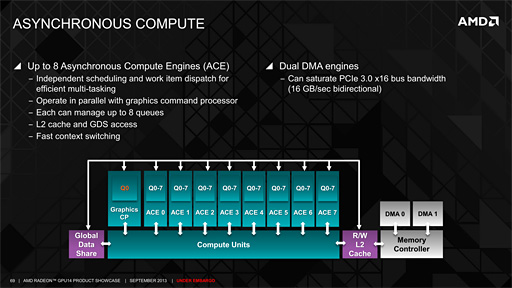 |
なお,上の図で「Graphics CP」とあるのはCommand Processorで,グラフィックスレンダリングタスクをGPGPUタスクと完全に並列で発行できるようになっている。さらに各Shader Engine内のCompute Unit群も,グラフィックスレンダリングとGPGPUの並列実行を仕掛けることが可能だ。
ただし,Command Processorは図でも分かるように1基しかなく,単一のグラフィックスレンダリングしか発注できない。たとえば「動的な環境マップの生成と局所的なシャドウマップ生成などを同時に発注してレンダリングする」といったことは無理で,現状は,レンダリングタスクが1つ終わってから,あらためて発注する流れを取る必要がある。この点についてMantor氏が「別のコンテクストのグラフィックスレンダリングに対応するのは次世代以降。乞うご期待」と述べていたことを付記しておきたい。
CrossFire動作のための
専用DMA「XMDA」を搭載
AMDは,複数のGPUを駆使してより高いGPU性能を実現するためのソリューションとして「CrossFire」(旧称:CrossFireX)技術を提供してきた。そして従来,CrossFire動作させるためには,2枚以上のグラフィックスカード間を専用のブリッジケーブルで接続する必要があった。
Radeon R9 290シリーズからは,このブリッジケーブルなしでCrossFire接続が可能になる。
 |
簡単に言うと,この新しいCrossFireでは,従来,ブリッジケーブル経由で行っていた各GPU間のデータ伝送を,マザーボード側のPCI Expressリンク経由で行うようにしたものだ。接続バスがPCI Express 3.0となり,実効データ転送レートがPCI Express 2.0以前と比較して飛躍的に向上したことから,こうした判断がなされたのだと思われる。
実際のデータ転送は,「CrossFire XMDA」と名付けられた専用のDMAエンジンによって行う。つまり,CPU側やGPUコア側の都合を気にせず,非同期かつ自動的にPCI Express経由でGPU同士のデータ伝送が行えるということだ。
Radeon R9 290シリーズだけでなく
Radeon R9&R7 200シリーズはDirectX 11.2対応
Radeon R9 290シリーズは,Windows 8.1と連動して提供されるDirectX 11.2に対応する。
DirectX 11.2にはいくつかの注目ポイントがあるが,なかでもゲーム開発者達に歓迎されているのが,「Tiled Resources」(タイルドリソース)と呼ばれる新機能だ。
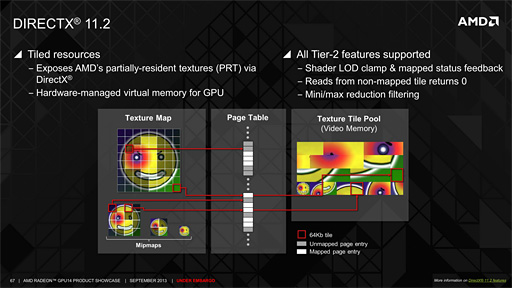 |
このTiled Resourcesには幾つかの活用手法があるが,最もシンプルで分かりやすいのは「仮想テクスチャ」(バーチャルテクスチャ)として利用する手法だ。
Windowsに限らず,一般的なOSには,物理メモリに乗り切らないデータをHDD上に退避する仮想メモリ(バーチャルメモリ)という機能が提供されている。その処理を「スワップ」と呼ぶことを知っている人も多いだろう。
CPUがその仮想メモリにアクセスする場合,HDD上に退避されていたデータを物理メモリに再度読み出すことで対処するわけだが,この仮想メモリとスワップの概念をGPUのテクスチャアクセスに当てはめたのが仮想テクスチャだ。つまりTiled Resourcesとは,グラフィックスメモリに乗り切らないほどの巨大なテクスチャを仮想メモリ的に外部ストレージへと退避し,必要なとき,自動的にメインメモリに書き戻すようなテクスチャシステムのことなのである。
これまでも,グラフィックスメモリに乗り切らないほどの巨大サイズのテクスチャをメインメモリ側に置いて取り扱うこと自体は行えた。PCI Expressが登場する前,AGP(Accelarated Graphics Port)時代には,メインメモリの一部をGPUからアクセスできるようにするGART(Graphics Address Remapping Table)の概念が規定され,「AGPメモリ」機能などと呼ばれていたので,憶えている人もいるだろう。
そしてこれはPCI Express時代にも受け継がれたが,その「メインメモリ側に置かれたデータ」のハンドリングは,ゲームデベロッパ側が自前で構築したソフトウェアで行う必要があるという制限があった。たとえばid Softwareのゲームエンジン「id Tech 5」は,数十GBにおよぶ巨大なテクスチャのストリーミング機能「Mega Texture」を利用できるが,このMega Textureなどはまさしく「自前でなんとかする」代表的な例である。Tiled Resourcesによって,こういった機能がAPIレベルでサポートされたというわけだ。
なお,Tiled Resourceは,PlayStation 4やXbox OneのAPU内のGPUコアだけでなく,Southern Islands世代のリネームモデルとして登場したRadeon R9 280X以下のRadeon R9&R7 200シリーズでも対応している。なぜSouthern Islands世代のGPUコアでもDirectX 11.2をサポートできるのかというと,もともとTiled Resourcesの機能概念自体が,AMDがOpenGLにおける独自拡張機能として提供してきた機能「Partially-Residient Textures」(パーシャリ―レジデントテクスチャ)をDirectX上で一般化したものだからである。
おわりに〜DirectX 11.2対応ゲームはいつ出てくるのか?
前世代と比べるとトランジスタ数が約44%増え,チップサイズが約24%増えて理論性能値が約30%向上したわけで,端的にまとめるならば「順当な進化」といったところだろうか。
これはそれだけ,GCNコアが,スケーラブルに性能を強化しやすいアーキテクチャであると証明されたともいえる。今後もしばらくは,GCNアーキテクチャベースのRadeonが広くリリースされ続けることだろう。
 |
今回発表されたRadeon R9 290シリーズがDirectX 11.2対応GPUということで,今後,DirectX 11.2対応ゲームタイトルがどれだけリリースされるのか気になる人もいると思うが,しかし短期的に見た場合,ゲームスタジオがTiled Resource機能などを積極的に活用する可能性は低いと思われる。
Tiled ResourceはGPUにおける仮想メモリの概念をハードウェアとOSで自動的に制御する仕組みだけに,DirectX 11.2はWindows 8.1にのみに提供される方針となっている。Windows 8ユーザーはWindows 8.1への無償アップグレードが可能なので,その点は問題ないだろうが,ゲームスタジオとしては,依然として多く存在するWindows 7ユーザー(やWindows Vista+Service Pack 2のユーザー)を足切りする判断はしにくい。そして,テクスチャリングシステムはゲームエンジンの根幹システムとなるため,Tiled Resources使用版と未使用版の2バージョンを作り分ける方針もとりにくいのだ。
ただ,長期的視点で見れば,いずれ積極活用されるようになるのは間違いない。
というのも,前述のとおり,PlayStation 4とXbox OneのAPUがTiled Resourcesに対応しているからだ。現在流通しているゲームエンジンだと未対応ながら,いずれ対応は図られるはずで,そうなってくれば,必然的にマルチプラットフォーム展開されるPC版でも使われるということになる。
その意味において,当面の間,Radeon R9 290シリーズ,というよりもDirectX 11.2対応GPUは,新しいDirectX 11.0世代のGPUとして活用されることになるはずだ。
4GamerのRadeon R9 290Xレビュー記事
AMDのRadeon R9シリーズ製品情報ページ(英語)
- 関連タイトル:
 Radeon R9 200
Radeon R9 200 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー