










連載
西川善司の3DGE:Primitive Shader対Mesh Shaderの真実。ジオメトリパイプライン戦争の内幕とAMDのゲーマー向けGPU戦略
 |
役職名からも分かるとおり,Wang氏とBergman氏は,AMDにおけるRadeon GPU戦略の中心にいる人物である。インタビューでは,同社のGPU戦略について筆者が気になることのあれこれを聞けたので,その概要をレポートしよう。
 David Wang氏(Senior Vice President,Engineering,Radeon Technologies Group,AMD) |
 Rick Bergman氏(Executive Vice President,Computing and Graphics Business Group,AMD) |
Primitive Shaderはどこへ行ったのか
2000年に誕生して以来,近代GPUの基本技術基盤となっている「プログラマブルシェーダアーキテクチャ」は,今やPCやゲーム機のみならず,スマートフォンを含むさまざまな組み込み機器向けのGPUにも採用されるほど浸透している。しかし,その描画パイプラインは,2000年に登場して以来,増築と改築が繰り返されたため,とくにジオメトリパイプラインは,「もはや複雑すぎて使いにくい」と開発者から指摘されるようになってしまった。
これを受けて,AMDとNVIDIAは,ジオメトリパイプラインの刷新を巡る標準規格の座を,2017年頃から争い始めた。
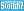
まず,2017年にAMDが,「Radeon RX Vega」の発表に合わせて「Primitive Shader」を提唱する(関連記事)。
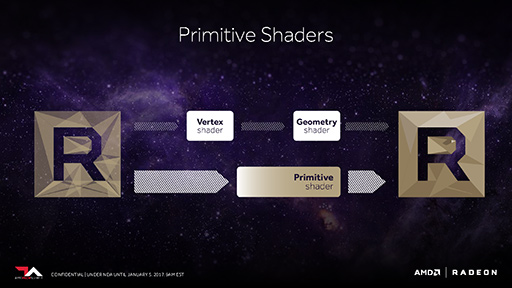 |
翌2018年になると,今度はNVIDIAが,「GeForce RTX 20」シリーズの発表に合わせて「Mesh Shader」を提唱した(関連記事)。
 |
そして2019年,Microsoftは,NVIDIAのMesh Shader案を「DirectX 12 Ultimate」における標準仕様に選んで,標準化争いは終結したわけだ。筆者は,まず一連の動きについて聞いてみた。
David Wang氏(以下,Wang氏)
 |
そうなると,AMDのPrimitive Shaderは,現在どのような扱いになっているのだろうか。ソニー・インタラクティブエンタテインメント(以下,SIE)は,PlayStation 5のGPUにおいて,Primitive Shader採用をアピールしたことがある(関連記事)。一方のMicrosoftは,Xbox Series X|S(以下,XSX)において,Mesh Shaderの採用をアピールしている(関連リンク)。
興味深いのは,PS5とXSXはどちらもほぼ同世代のAMD製GPUを搭載しているのに,新ジオメトリパイプラインについては,標準採用した技術が異なるという点だ。
Wang氏
確かに,DirectX 12に標準採用されたのはMesh Shaderだ。ただ,もともと新ジオメトリパイプライン構想は,煩雑化したジオメトリパイプラインを整理整頓して,ゲーム開発者から使いやすく,しかも性能を引き出しやすいものにしようというコンセプトから始まっている。つまり,AMDもNVIDIAも,発想の起点と掲げた目標は同じだったと言えよう。包み隠さず言えば,Primitive ShaderとMesh Shaderは,実装形態に差はあれど,機能としては似ているところが多い。
ではAMDは,Primitive Shaderを破棄したのか……というと,そうではない。ハードウェアとしては,今もPrimitive Shaderは存在しており,Mesh Shaderの使い方をPrimitive Shaderで実現する,そんなイメージでMesh Shaderに対応しているのだ。
4Gamer
すると,Radeon RX Vegaで「Primitive Shader搭載」をアピールして以降,Radeon VII,RDNA 1の「Radeon RX 5000」シリーズ,RDNA 2の「Radeon RX 6000」シリーズ,そしてRDNA 3の「Radeon RX 7000」シリーズにも,Primitive Shaderは存在しているということですか。
Wang氏
ハードウェアとしてのPrimitive Shaderは,Radeon RX Vega以降,最新のRDNA 3ベースGPUまで,すべてに存在している。DirectX 12から見たとき,Radeon GPUのPrimitive Shaderは,Mesh Shaderとして動作する仕組みになっているということだ。
4Gamer
新ジオメトリパイプラインは,Mesh Shaderで行くことで決着は付きましたが,正直,Mesh Shaderを積極的に活用したゲームタイトルは,筆者の知る限り,とても少ないです。実際,ゲーム開発の現場ではどのようになっているのでしょうか。
Wang氏
PS5のGPUは,AMD製のRDNAベースGPUであることから,Primitive Shaderを搭載しており,(※PS5のSDKから)ネイティブで利用できる。これにより,PS5専用ゲームタイトルでは,Primitive Shaderを効果的に活用しているものがある。
私の感覚では,PS5向けファーストパーティタイトルで,それなりにPrimitive Shaderが使われることもあって,Mesh Shaderの活用事例数を上回っているのだと思う。それに比べると,Mesh Shaderは業界標準となったものの,近年のゲーム作品でMesh Shaderを積極活用した事例は,ほとんどないと思われるのだが,どうだろうか。
ちなみに,Wang氏の説明どおりならば,XSXのGPUもRDNAベースなので,Primitive Shaderを搭載していることになり,これをDirectX 12からMesh Shaderとして活用する実装形態になっているということになる。
さて,AMDのGPUにおけるPrimitive Shaderを,Mesh Shader的に活用できることは理解できた。しかし,ゲームにおける3Dモデルのデータ構造と描画パイプラインの動かし方は,Primitive ShaderやMesh Shaderと,従来型の描画パイプラインでは異なってくる。そのため,ゲーム開発側からすると,同一タイトルをPrimitive Shader/Mesh Shaderを使う場合と使わない場合で,描画パイプラインの設計とデータの持ち方を作り分けなくてはならない。これは,ゲーム開発側にとっては面倒なことだ(※ゲームエンジンがMesh Shaderに対応してくれれば,手間をある程度減らすことは可能だろう)。
新ジオメトリパイプラインとしてMesh Shaderが業界標準の規格となり,事実上,Primitive Shaderを吸収したところまではよかった。しかし,実際は作り分けが必要なのであれば,「そんな面倒なもの積極的には使いたくない」とゲーム開発側が考えることもあろう。そんなわけで,Primitive ShaderもMesh Shaderも,実際にはなかなか積極活用されないという現状につながっているのかもしれない。
AMDが考える次世代グラフィックスパイプライン
ジオメトリパイプラインの標準化戦争では,NVIDIA案が採用されたものの,これまでもAMDは,3Dグラフィックス技術の標準化において,数々の成果を上げている
たとえば,DirectX 11登場時に標準化された,ポリゴンをプログラマブルに分割する機構「テッセレーションステージ」は,Radeon HD 2000シリーズでAMDが独自に実装したテッセレーション機能をベースにして標準化したものだ。
VESAの「Adaptive-Sync」や,HDMIの「Variable Refresh Rate」(VRR)といった,GPU主導のディスプレイ同期技術も,AMDが提唱した「FreeSync」がベースとなっている。
さらに,抽象化レイヤーを薄くしてリアルタイム性を高めたグラフィックスAPI「DirectX 12」は,AMDが提唱した「Mantle」のアイデアがベースとなっており,実際,Mantleそのものが,OpenGL陣営の「Vulkan」として標準採用されたこともあった。
それでは,今後はどうなるのだろうか。
4Gamer
今後,グラフィックス業界で,新たに起きそうな標準化すべき3Dグラフィックスパラダイムは何でしょうか。
Wang氏
とあるパートナーと我々が研究開発を進めているのは,CPUの助けを借りずに,GPUだけでグラフィックス処理タスクを生成して,それをGPU自身で消費するGPU自己完結型の描画パイプライン駆動技術だ。
CPU側のシステムメモリと,GPU側のグラフィックスメモリとの間でのデータ伝送を極力省けるだけでなく,描画コマンドをCPUから伝送する仕組みをも省略できることから,相当に高い性能を実現できる新技術になる。
Wang氏の話を聞いた限りでは,「Multi Draw Indirect」(以下,MDI)に関係が深そうなものに思える。Draw Indirectとは,あらかじめGPUに伝送しておいた3Dモデルなどを,パラメータを変えて反復描画する「インスタンス描画」を,GPU主導で行う仕組みである。
そしてMDIとは,これを複数回行う仕組みと考えればいい。たとえば,数百万個ものパーティクルを,CPUがほぼ介入することなく,GPU主導で簡易的なシミュレーション実行と描画までを行うGPUパーティクルの仕組みは,ゲームエンジンなどで実用化されて久しいものだ。
AMDのRDNA 3世代GPUでは,MDIをハードウェアで処理する「Multi Draw Indirect Accelerator」(MDIA)を搭載している。これにより,RDNA 2比でMDIの実行が2.3倍も高速化すると,AMDはアピールしていた。
先述したMesh Shaderでは,1体の3Dモデルを複数のパーツ(ドメイン)に分割して取り扱う「Meshlet」(メッシュレット)単位で描画する。MDIはこの描画を高速に処理する用途への利用を期待されている(関連リンク)。
たとえば,遠近に応じて精細度の異なる3Dモデルを置き換えるクラシックなLevel of Detail(LoD)の仕組みに変わる技術として,Meshletを活用するアイデアが提唱されているので,興味のある人は次の動画を見てほしい。
Wang氏は,「我々としては,これをGPUプログラミングモデルの新しい標準仕様として提唱していきたいと考えている。いずれ,然るべきタイミングが来たときに発表できるだろう」とも述べていた。RDNA 4世代のGPUでは,これが新機能として搭載されるのであろうか。なかなか面白そうである。
「GPUによるAI支援機能」をAMDはどう考えているか
AMDは,RDNA 3アーキテクチャにおいて,GPUに推論アクセラレータ「AI Accelerator」を組み込んだ。これは,NVIDIAのGeForce RTXシリーズにおける「Tensor Core」に相当するものだ。すでにIntelも,単体GPUの「Intel Arc」シリーズに同種の「Xe Matrix Engine」(XMX)を搭載しているので,結果的にAMDは,GPUへの推論アクセラレータ搭載では最後発となってしまったわけだ(関連記事)。
 |
ところで,RDNA 3世代GPUの最上位モデルであるRadeon RX 7900 XTXの推論アクセラレータの16bit浮動小数点(FP16)の理論性能値は,約123 TFLOPSとなっていた。一方で,NVIDIAの「GeForce RTX 4090」におけるTensor CoreのFP16理論性能値は,約330 TFLOPS,GeForce RTX 4080が約195 TFLOPSなので,かなり水を開けられている。
さらに,IntelのデスクトップPC向けGPU「Intel Arc A770」では,XMXのFP16理論性能値が約138 TFLOPSなので,RDNA 3世代GPUにおける推論アクセラレータの性能は,ずいぶんと控えめになる。
4Gamer
AMDは,GPUへの推論アクセラレータ搭載について,どう考えているのですか。
Wang氏
推論処理については,最新世代のCPUであれば十分な速さで行える。世に出回っているAI技術活用の推論処理は,約95%がCPUで行われているのが実情だ。データセンターなどにおけるAI処理も同様で,我々のサーバー向けCPU「EPYC」も,さまざまな現場で多くのAI処理を行っている。
一方で,GPUが担当すべきAI処理とは,AIの学習(トレーニング)用の処理系だと思っている。我々は,機械学習分野におけるGPU活用を支援する枠組みとして,AMD製GPUのGPGPUプラットフォーム「Radeon Open Compute Platform」(ROCm)を提供しており,主要なAI開発フレームワークであるTensorFlowや,PyTorchへも対応済みだ。その意味では,今では,NVIDIAの「CUDA」プラットフォームに対して引け目を感じている部分はない。
4Gamer
だとしても,今回のRadeon RX 7900 XTXにおいては,推論アクセラレータの性能がやや控えめな印象を受けます。
Wang氏
 |
我々は,GPUに搭載した推論アクセラレータで行うべきなのは,NVIDIAがやっているような「DLSS」に代表される「画像処理中心の活用」だけに留まるべきではないと思っている。
「FidelityFX」シリーズのひとつである「FidelityFX SuperResolution」(FSR)を見てほしい。推論アクセラレータを活用することなく実現したFSRのアンチエイリアス処理や超解像処理は,NVIDIAのDLSSに十分対抗しうる性能と品質をもたらせている。
AI技術を用いずとも行える用途に対してまで,NVIDIAが積極的にAI技術を活用しようとするのは,NVIDIAがGPU内に大規模な推論アクセラレータを搭載してしまっているからだ。それを有効活用するために,多くの推論アクセラレータを動員する必要があるテーマに取り組んでいるのだろう。それは彼らのGPU戦略であり,それはそれで素晴らしいことだが,だからといって我々も同じ戦略を取るべきだとは考えていない。
我々は,民生向けGPUにおいて,ユーザーが望んだり,ユーザーに楽しみを与えるために必要なスペックを盛り込むことに注力している。そうしないと,ユーザーは,使いもしない機能にお金を払っていることになるからだ。我々はゲーマーが手にするGPUに実装すべき推論アクセラレータは,ゲームがより高度で楽しくなる方向に活用するべきだと思っている。
 |
4Gamer
それらは具体的にどんなテーマになりますか。
Wang氏
たとえば,敵キャラクターやNPCなどの動き,振る舞いなどが,最も分かりやすい事例だろう。
また,AIを映像処理に利用するにしても,より高度な処理をAIに担当させるべきだ。具体的には,最近,3Dグラフィックス業界で盛り上がりつつある「ニューラルグラフィックス」などのテーマがふさわしいかもしれない。
敵やNPCを賢くする,あるいは知的に見せるという用途にAI技術を適用するのは,ゲームのゲームメカニクス設計に大きくかかわるので,GPU性能によっては愚かに振る舞うようでは困りそうだが,主張としては理解できる。
ちなみに,ニューラルグラフィックスは,AI技術の支援を受けながらグラフィックスパイプラインを加速化したり,品質を上げたり,あるいは,新しいCGコンテンツを生成するような幅広い技術だ。
NVIDIAも注力し始めている(関連リンク)。3Dキャラクターを,モーションキャプチャした人間の演技データで動かす技術は,今やありふれたものだが,NVIDIAは無数のモーションキャプチャデータから,そのシーンにおける最適な姿勢制御を選択するAIアニメーション技術として「Adversarial Skill Embedding」(ASE)という手法を発表した。これも,AI技術を3Dグラフィックスのアニメーションに適用するニューラルグラフィックス技術の一例だ。
最もシンプルかつ直接的なニューラルグラフィックスは,DLSSのようなAI技術で映像の品質を向上させる取り組みである。また,「Stable Diffusion」に代表されるAI画像生成技術や,2D画像から3Dグラフィックスを生成する取り組みなども,ニューラルグラフィックスの一種といえなくなさそうだ。
AMDやNVIDIAが,リアルタイム性の高いゲームグラフィックス向けに有望だとして取り組み始めたニューラルグラフィックスのテーマには,もう少し基本的なジャンルもある。具体的には,3Dゲームグラフィックスのさまざまな要素をまじめに演算するのではなく,AIベースの推論でそれっぽく仕立ててしまう取り組みだ。
たとえば,直接光によるライティング程度なら,GPUに計算させたほうが速くて正確だが,間接光を含めた大局照明によるライティングは,見栄えでは曖昧なものになるのに,必要な演算量は膨大だ。ゲームグラフィックスは,説得力があれば正確性は気にしなくていいとされるケースも多いので,そういったテーマは,ニューラルグラフィックスが適しているといえる。
一例としてNVIDIAは,Deferred Rendering時に生成する「G-Buffer」の内容を手がかりに,AIの支援を活用して3Dシーンの間接照明を生成する大局照明技術を,SIGGRAPH 2020で発表したことがある。
とは言うものの,RDNA 3のAI Acceleratorをどうやってニューラルグラフィックスに使ったらいいのか,AMDは示していない。当面は,IntelのXMXなどと同じく,「Shader Model 6.4」(以下,SM 6.4)からの活用になるようだ(関連リンク)。
この点についても,Wang氏に聞いてみた。
Wang氏
一般的なAIアプリ開発においては,先に述べたようにメジャーなAI開発フレームワークを使うことになるだろう。それ以外,ゲームをはじめとしたリアルタイム性の高いAIソリューション開発には,「DirectML」や「Vulkan ML」を使うことになるだろう。
ちなみに,Radeon RX 7900シリーズが発表されたときに,GPUで動作するStable Diffusionを公開したが,あれはVulkan ML上で実装したものだ。
 |
AMDのGPU戦略は今後どこへ向かう?
最後に,今後のAMDにおけるGPU戦略について,Wang氏とBergman氏に聞いてみた。
Rick Bergman氏(以下,Bergman氏)
 |
近年では,Samsung Electronics製SoCの「Exynos 2200」に,RDNA 2ベースのGPU IPコアを提供するなどスマートフォン分野にも進出した。また,電気自動車メーカーのテスラに対して,同社の「Model S」と「Model X」の車載システムにも,AMDのGPUを提供するまでに至った。新分野への進出だ。今後も,ゲーマーの期待を裏切らないGPU開発を行っていくつもりだ。
 |
 |
Wang氏
2020年以降,AMDは,HPC分野に向けてはCDNAベースのGPU開発を行っており,ゲーマーに向けてはRDNAベースのGPU開発を行うといった具合に,GPUの開発設計方針を分化した。当面はこの流れで行くことになる。
現在のAMDは,スマートフォン向けGPUには数Wクラスで駆動できるものを提供しており,HPC向けGPUともなれば,1000Wオーバーで動作する世界最高レベルの演算ソリューションを提供している。つまり,各分野でそれぞれ最高クラスのグラフィックス性能を提供することができるわけだ。今後もAMDは,我々のGPU技術があらゆる分野に浸透していくことを目指して研究開発を行っていく。
最後に,冗談ぽい質問をぶつけてみた。
NVIDIAのSoC「Tegra X1」がNintendo Switchに採用された2017年以前,AMDは,「我々のプロセッサは,ソニー(当時はPlayStation 4)とMicrosoft(同 Xbox One),任天堂(同 Wii U)という3つの家庭用ゲーム機で採用されている」と語っていたが,今は2つになってしまっている。これについて,「何か言いたいことは?」と,2人にコメントを求めてみた。
 |
Bergman氏
任天堂とは,またビジネスができたらいいな……とは常日頃,思っているよ(笑) 我々は,常にいいソリューションを用意しているからね。彼らがまた,我々の元に帰ってきてくれることに期待しているよ(笑)。
Wang氏
君(筆者)は何か忘れていないか? 我々は,今でもPS5,XSXの2つに加えて,3つめの家庭用ゲーム機に向けてプロセッサを提供しているじゃないか。3つめは何かって? それは,Valveの「Steam Deck」だよ(笑)。
AMD公式Webサイト
- 関連タイトル:
 Radeon RX 7000
Radeon RX 7000 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー