










連載
西川善司の3DGE:驚異の64コア128スレッド対応。AMDの次世代モンスターCPU「Rome」はどんな構造になっているのか
北米時間2018年11月6日,TSMCの7nmプロセス技術を用いて製造される世界初のx86 CPU「Rome」(ローマ,開発コードネーム)とGPU「Vega 7nm」(ヴェガ7nm,同)をAMDが予告した(関連記事)。
予告に合わせてAMDは,集まった報道関係者を対象として現時点での技術説明会も実施しているのだが,本稿ではその中から,CPUパートの概要を紹介してみたい。要するに,CPUマイクロアーキテクチャ「Zen 2」と,Zen 2ベースのサーバーおよびデータセンター向けCPUとして最大64コア128スレッド対応を実現するRomeについて,ということだが,まず,7日掲載の記事でAMDの社長兼CEOであるLisa Su(リサ・スー)博士の掲げたRomeは,氏いわく「本物」とのことだ。
なので本物だという前提で話を進めるが,CPUパッケージ中央に大きな長方形のシリコンダイがあり,それを左右から挟み込むように4個ずつ,計8個の小型シリコンダイを実装する構成になっているのが分かるだろう。
7nmプロセス技術を用いて製造されるZen 2マイクロアーキテクチャベースのCPUコアは,8個ある小型シリコンダイのほうに8基ずつ載るのである。小型シリコンダイ(以下,CPUダイ)あたり8コア16スレッドに対応するのは「Zen」および「Zen+」世代と変わらないため,それを8基搭載することにより最大64コア128スレッド対応を実現する計算だ。
では,中央にある大きなシリコンダイは何かというと,これは14nmプロセス技術を用いて製造される「I/O Die」(以下,I/Oダイ)である。
簡単に言えばI/Oダイは,かつてマザーボードの中央で偉そうに鎮座していたノースブリッジに相当するものだ。Romeにおいてはプロセッサ間インタフェースを提供する「Infinity Fabric」とそのクロスバースイッチ,DDR4メモリコントローラ,そしてPCI Express(以下,PCIe)Gen.4コントローラなどを統合している。
ではどうしてI/Oダイは14nm世代に留まるのだろう? Zen 2ベースで8基のCPUコアを搭載するCPUダイと同じく7nm世代へ移行すればいいのにと思う読者も多いと思うが,これはI/O(=入出力)に関わるデバイス類の電圧が大きいためだと,AMDのMark Papermaster(マーク・ペーパーマスター)CTO兼テクノロジー&エンジニアリング部門上級副社長は述べていた。DDRメモリは1.2V以上,PCIeには3V以上もの電圧がかかるが,現在のところ,7nmプロセス技術の配線はそこまで高い電圧を流すことが想定されてないのだそうだ。
Zen,そしてZen+マイクロアーキテクチャでは,CPUコアを8基――正確を期すと,4基1組の「CPU Complex」(公式略称「CCX」。以下略称表記)を2基――統合したシリコンダイごとにInfinity FabricもメモリコントローラもPCIeコントローラも搭載している。そのため,デスクトップPC向けRyzenはともかく,EPYCやRyzen Threadripperのように1つのCPUパッケージ上で複数のCPUダイを搭載するプロセッサでは,一部のI/O機能が重複してしまい,重複する部分では適宜無効化するような“無駄”が生じる結果となっていた。
その無駄を,8個ものシリコンダイを1パッケージ化するときにも許容することはできないというのが,AMDの判断なのだろう。結果としてZen 2世代ではCPUダイとI/Oダイとに分かれ,そうした無駄は排除されることになったわけだ。
しかしこのことは,もしRomeと同じCPUダイを使ってデスクトップPC向けRyzenを展開する場合,8コア16スレッド対応のCPUダイとは別にI/Oダイが必要になるということと同義でもある。さすがにEPYCが採用しているのと同じ巨大なI/Oダイを使うというのは考えにくいため,CPUダイ1〜2個程度の規模に最適化したI/Oダイを別途起こすことになるだろう。
そしてその場合は,マルチダイパッケージのプロセッサとなり,コスト的にZen+世代までと比べて高くつくことは必至である。AMDは現在,Zen 2世代のデスクトップPC向けRyzenの計画については何も発表していないので,机上の空論に過ぎないわけだが,このあたり,Zen 2世代でAMDがどのように舵取りをするのかは今からとても気になるところである。
続いてはZen 2マイクロアーキテクチャに目を向けてみるが,AMDは今回の説明会で,いくつか改良ポイントを明らかにしている。
まず,フロントエンドには細かく改良が入った。
あらためて言うまでもないが,Zen世代のプロセッサはx86アーキテクチャ準拠であり,命令セットとしては「CISC」(Complex Instruction Set Computer,シスク)を採用している。
そしてこれまた釈迦に説法だと思うが,CISCでは命令語のバイナリが可変長構造になったり,命令実行にかかる時間がまちまちになったりして,多段パイプラインでの実行が難しい。そこで最近のx86プロセッサでは「表向きはCISCだが,内部の実行スタイルはRISC」といったスタイルが主流となっており,長いCISC命令を短い固定長の内部RISC命令に変換して実行している。この内部RISC命令を「μOp」(もしくは「Micro Operation」)と呼ぶが,Zen 2ではこのμOp用となるキャッシュメモリの容量を増加させることで利用効率を向上させており,さらにメモリから読み出したx86命令そのものをキャッシュする効率の最適化も行っているという。
Zenマイクロアーキテクチャでは,過去の分岐履歴から次の分岐予測を行うときに「過去に行った予測の合否」をフィードバックさせて分岐予測精度を上げるという機械学習AIチックな「Neural Net Predicion」メカニズムを分岐予測に採用しているのだが,Zen 2では,分岐先アドレスのx86命令を先読みするプリフェッチ動作に改善を施したそうだ。
以上の改良により,クロックあたりの命令実行数(IPC,Instructions Per Clock)はZen+世代と比べて向上しているとのことである。ただし,具体的にどれくらい向上したかは,まだ明らかになっていない。
Zen 2世代では,浮動小数点演算性能にも改善が入る。
具体的には,これまで128bit幅だった浮動小数点レジスタが2倍の256bitとなる。AVX(Advanced Vector Extensions)を使った浮動小数点SIMD演算において,従来だと4要素並列(32bit×4=128bit)演算を1回で行えていたところが,Zen 2では8要素並列(32bit×8=256bit)演算を1回で処理できるようになるということだ。
それに伴い,ロード/ストアユニットも256bit幅ベクトルデータの読み出しおよび書き込みに対応するので,簡単にまとめるなら「AVX命令の実行効率が向上する」ことになる。
なお,従来同様,AVX-512には対応しない。
そのほか,プロセッサ業界で最近のホットトピックとなっている「セキュリティホール問題」のうち,「Spectre」と呼ばれる問題などに対し,ハードウェアレベルの対策も入っているとのことだった。
11月7日掲載の記事でもお伝えしているとおり,Romeのリリース時期は2019年内となっている。前半か後半かすらも「明言しない」とAMDは宣言しているのだが,一方で「まだ性能チューニングは行っておらず,また,定格クロックでの動作でもない。これは『オーバークロックしている』という意味でもない」いう入念な(?)前置きとともに,動作デモを披露している。
今回のデモは,ソフトウェアベースのレイトレーシングベンチマークである「C-RAY」で,競合と比較するというものだ。
用意されたのは,28コア56スレッド対応CPU「Xeon Platinum 8180M」を2基搭載したシステムと,32コア64スレッド対応の「EPYC 7601」を2基搭載したシステム,そして64コア128スレッド対応版Romeを1基搭載するシステムだが,処理に要した時間はスコアは順に約30秒,約28秒,約27秒だった。
AMD側のメッセージとしては「Romeであれば1ソケットシステムで既存の2ソケットシステムを性能で上回る」というものになるが,間接的には「Romeの2ソケットシステムならどんなにすごいことになるか,乞うご期待」とも言っているわけである。
実際,実動デモこそなかったものの,2ソケットシステムにRomeを2基搭載したサンプルの展示はあった。
前述のとおり,RomeではI/OダイによりPCIe Gen.4に初対応を果たすわけだが,現行のEPYC用プラットフォームでRomeに対応できることをAMDは明言している。そう,CPUを差し替えるだけでPCIe Gen.4環境を利用できるということである。
それだけでなく,次次世代EPYCとなる「Milan」(ミラン)も現行EPYCプラットフォームに対応するという。
このあたりはZenマイクロアーキテクチャがデビューしたときの予告どおり,ではあるのだが,いくつかの疑問は残る。
たとえばメモリだ。RomeがDDR4対応というのは納得できる話だが,Milanでもプラットフォームを共用するということは,そのタイミングでもDDR4を使うと予告しているにほぼ等しい。もちろん,次次世代EPYCであるMilanがいつ出るのかという話次第ではあるのだが,2019年後半にはDDR5メモリの量産が始まる見込みになっており,業界全体としてDDR5への移行ロードマップが固まる兆しも出てきているだけに,このあたりは興味深い。
「DDR5対応I/Oダイ」も作ることで対応すればいいだけかもしれないが。
また,互換性の話からは離れるが,現行のEPYCと同じ8chのDDR4メモリコントローラで,よりCPUコア数の増えるRomeやMilanと性能面のバランスが取れるかというのも気になるところだ。CPUコア数が倍々ゲームで増えていくのに,メモリインタフェースが据え置きで問題ないのか,ここがボトルネックになり得ないか,というのはやはり心配である。
このあたりの詳細は,Romeの正式発表が近づくにつれ,徐々に明らかとなっていくだろう。Romeのスペックは,次世代Ryzen Threadripper,そして次世代Ryzenのスペックを占ううえでも重要なものだけに,今後も継続して追いかけていきたいと思う。
 |
 |
なので本物だという前提で話を進めるが,CPUパッケージ中央に大きな長方形のシリコンダイがあり,それを左右から挟み込むように4個ずつ,計8個の小型シリコンダイを実装する構成になっているのが分かるだろう。
 |
では,中央にある大きなシリコンダイは何かというと,これは14nmプロセス技術を用いて製造される「I/O Die」(以下,I/Oダイ)である。
簡単に言えばI/Oダイは,かつてマザーボードの中央で偉そうに鎮座していたノースブリッジに相当するものだ。Romeにおいてはプロセッサ間インタフェースを提供する「Infinity Fabric」とそのクロスバースイッチ,DDR4メモリコントローラ,そしてPCI Express(以下,PCIe)Gen.4コントローラなどを統合している。
 |
 |
 |
Zen,そしてZen+マイクロアーキテクチャでは,CPUコアを8基――正確を期すと,4基1組の「CPU Complex」(公式略称「CCX」。以下略称表記)を2基――統合したシリコンダイごとにInfinity FabricもメモリコントローラもPCIeコントローラも搭載している。そのため,デスクトップPC向けRyzenはともかく,EPYCやRyzen Threadripperのように1つのCPUパッケージ上で複数のCPUダイを搭載するプロセッサでは,一部のI/O機能が重複してしまい,重複する部分では適宜無効化するような“無駄”が生じる結果となっていた。
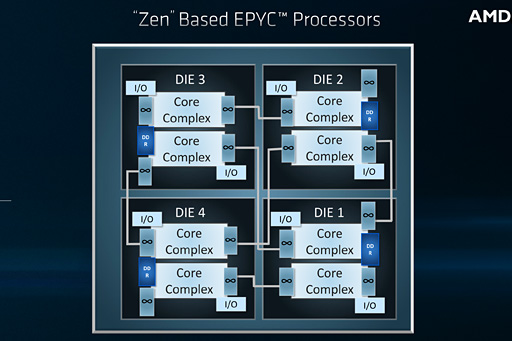 |
その無駄を,8個ものシリコンダイを1パッケージ化するときにも許容することはできないというのが,AMDの判断なのだろう。結果としてZen 2世代ではCPUダイとI/Oダイとに分かれ,そうした無駄は排除されることになったわけだ。
しかしこのことは,もしRomeと同じCPUダイを使ってデスクトップPC向けRyzenを展開する場合,8コア16スレッド対応のCPUダイとは別にI/Oダイが必要になるということと同義でもある。さすがにEPYCが採用しているのと同じ巨大なI/Oダイを使うというのは考えにくいため,CPUダイ1〜2個程度の規模に最適化したI/Oダイを別途起こすことになるだろう。
そしてその場合は,マルチダイパッケージのプロセッサとなり,コスト的にZen+世代までと比べて高くつくことは必至である。AMDは現在,Zen 2世代のデスクトップPC向けRyzenの計画については何も発表していないので,机上の空論に過ぎないわけだが,このあたり,Zen 2世代でAMDがどのように舵取りをするのかは今からとても気になるところである。
Zen 2では何が改善しているのか(2018年11月版)
続いてはZen 2マイクロアーキテクチャに目を向けてみるが,AMDは今回の説明会で,いくつか改良ポイントを明らかにしている。
まず,フロントエンドには細かく改良が入った。
あらためて言うまでもないが,Zen世代のプロセッサはx86アーキテクチャ準拠であり,命令セットとしては「CISC」(Complex Instruction Set Computer,シスク)を採用している。
そしてこれまた釈迦に説法だと思うが,CISCでは命令語のバイナリが可変長構造になったり,命令実行にかかる時間がまちまちになったりして,多段パイプラインでの実行が難しい。そこで最近のx86プロセッサでは「表向きはCISCだが,内部の実行スタイルはRISC」といったスタイルが主流となっており,長いCISC命令を短い固定長の内部RISC命令に変換して実行している。この内部RISC命令を「μOp」(もしくは「Micro Operation」)と呼ぶが,Zen 2ではこのμOp用となるキャッシュメモリの容量を増加させることで利用効率を向上させており,さらにメモリから読み出したx86命令そのものをキャッシュする効率の最適化も行っているという。
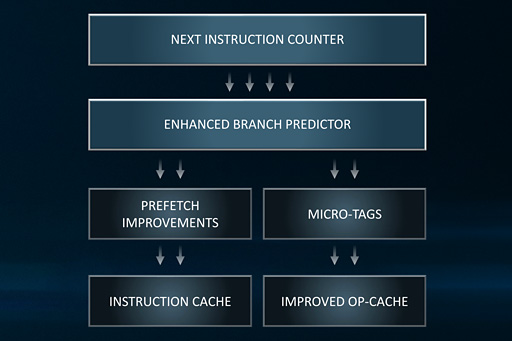 |
Zenマイクロアーキテクチャでは,過去の分岐履歴から次の分岐予測を行うときに「過去に行った予測の合否」をフィードバックさせて分岐予測精度を上げるという機械学習AIチックな「Neural Net Predicion」メカニズムを分岐予測に採用しているのだが,Zen 2では,分岐先アドレスのx86命令を先読みするプリフェッチ動作に改善を施したそうだ。
以上の改良により,クロックあたりの命令実行数(IPC,Instructions Per Clock)はZen+世代と比べて向上しているとのことである。ただし,具体的にどれくらい向上したかは,まだ明らかになっていない。
 |
Zen 2世代では,浮動小数点演算性能にも改善が入る。
具体的には,これまで128bit幅だった浮動小数点レジスタが2倍の256bitとなる。AVX(Advanced Vector Extensions)を使った浮動小数点SIMD演算において,従来だと4要素並列(32bit×4=128bit)演算を1回で行えていたところが,Zen 2では8要素並列(32bit×8=256bit)演算を1回で処理できるようになるということだ。
それに伴い,ロード/ストアユニットも256bit幅ベクトルデータの読み出しおよび書き込みに対応するので,簡単にまとめるなら「AVX命令の実行効率が向上する」ことになる。
なお,従来同様,AVX-512には対応しない。
 |
そのほか,プロセッサ業界で最近のホットトピックとなっている「セキュリティホール問題」のうち,「Spectre」と呼ばれる問題などに対し,ハードウェアレベルの対策も入っているとのことだった。
2ソケットシステムの性能を1ソケットシステムで提供するRome
11月7日掲載の記事でもお伝えしているとおり,Romeのリリース時期は2019年内となっている。前半か後半かすらも「明言しない」とAMDは宣言しているのだが,一方で「まだ性能チューニングは行っておらず,また,定格クロックでの動作でもない。これは『オーバークロックしている』という意味でもない」いう入念な(?)前置きとともに,動作デモを披露している。
今回のデモは,ソフトウェアベースのレイトレーシングベンチマークである「C-RAY」で,競合と比較するというものだ。
用意されたのは,28コア56スレッド対応CPU「Xeon Platinum 8180M」を2基搭載したシステムと,32コア64スレッド対応の「EPYC 7601」を2基搭載したシステム,そして64コア128スレッド対応版Romeを1基搭載するシステムだが,処理に要した時間はスコアは順に約30秒,約28秒,約27秒だった。
AMD側のメッセージとしては「Romeであれば1ソケットシステムで既存の2ソケットシステムを性能で上回る」というものになるが,間接的には「Romeの2ソケットシステムならどんなにすごいことになるか,乞うご期待」とも言っているわけである。
実際,実動デモこそなかったものの,2ソケットシステムにRomeを2基搭載したサンプルの展示はあった。
 |
Rome,そして次次世代EPYC「Milan」の後方互換性は確保済み
 |
それだけでなく,次次世代EPYCとなる「Milan」(ミラン)も現行EPYCプラットフォームに対応するという。
 |
このあたりはZenマイクロアーキテクチャがデビューしたときの予告どおり,ではあるのだが,いくつかの疑問は残る。
たとえばメモリだ。RomeがDDR4対応というのは納得できる話だが,Milanでもプラットフォームを共用するということは,そのタイミングでもDDR4を使うと予告しているにほぼ等しい。もちろん,次次世代EPYCであるMilanがいつ出るのかという話次第ではあるのだが,2019年後半にはDDR5メモリの量産が始まる見込みになっており,業界全体としてDDR5への移行ロードマップが固まる兆しも出てきているだけに,このあたりは興味深い。
「DDR5対応I/Oダイ」も作ることで対応すればいいだけかもしれないが。
また,互換性の話からは離れるが,現行のEPYCと同じ8chのDDR4メモリコントローラで,よりCPUコア数の増えるRomeやMilanと性能面のバランスが取れるかというのも気になるところだ。CPUコア数が倍々ゲームで増えていくのに,メモリインタフェースが据え置きで問題ないのか,ここがボトルネックになり得ないか,というのはやはり心配である。
このあたりの詳細は,Romeの正式発表が近づくにつれ,徐々に明らかとなっていくだろう。Romeのスペックは,次世代Ryzen Threadripper,そして次世代Ryzenのスペックを占ううえでも重要なものだけに,今後も継続して追いかけていきたいと思う。
AMDの「Next Horizon」イベント特設ページ(英語)
AMD,64コア128スレッド対応の次世代EPYC「Rome」を予告。「Zen 3」「Zen 4」マイクロアーキテクチャ開発の進捗も明らかに
- 関連タイトル:
 EPYC
EPYC - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー