












テストレポート
Ivy Bridge基礎検証。CPUの基本性能やGPGPU性能などから,Sandy Bridgeとの違いを徹底的に探ってみる
 |
| Ivy Bridgeの製品イメージ |
 |
| Ivy BridgeはTick-Tock戦略におけるTickのプロセッサだ |
 |
| Ivy Bridgeの製造にあたってIntelが採用した3Dトライゲート・トランジスタ |
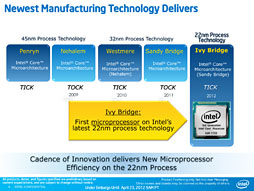
IntelはCore 2時代の後半以降,約1年ごとにプロセスの微細化と新世代アーキテクチャの導入を繰り返し,約2年でプラットフォームを一新するという,「Tick-Tock」(チクタク)戦略を採用している。そして今回のIvy Bridgeは「Tick」なので,製造プロセスの世代が切り替わる番の製品となる。
従来の「Sandy Bridge」(サンディブリッジ)コアだと32nm High-kメタルゲートプロセスを採用していたのに対し,Ivy Bridgeでは,マイクロアーキテクチャこそSandy Bridge時代と同じ「Intel Microarchitecture(Sandy Bridge)」ながら,3次元トライゲート(3D Tri-Gate)・トランジスタを用いた22nmプロセスを採用するというのが大きなトピックだ。
3次元トライゲート・トランジスタについては2011年5月6日の記事「Intelが発表した『3次元トライゲート・トランジスタ』って何だ? 『Ivy Bridgeの性能を大きく引き上げる技術』の正体に迫る」が詳しいが,ここで注目すべきは,マイクロアーキテクチャ側の変更がとくにないとはいっても,3次元トライゲート・トランジスタが持つ物理的な特性から,32nm世代のプレーナ・トランジスタ(Planar Transistor)からは1対1で置き換えられるわけではないという点だ。当然,細かな再設計が行われ,その結果として,性能面に多少の違いが出てくる可能性はある。
また,マイクロアーキテクチャ側の変更がとくにないとされる一方で,下記のとおり,いくつか興味深い拡張が行われたことは指摘しておく必要があるだろう。
- PCI Express 3.0対応
- 統合型グラフィックス機能によるDirectX 11&OpenCL対応
- デュアルチャネルDDR3-1600メモリコントローラ統合
 |
4GamerではCPUコア編とGPUコア編に分けて,ゲーム用途を前提とした性能検証を行っている。そのなかでPCI Express 3.0やDirectX 11に対応した統合型グラフィックス機能(以下,iGPU)の検証はもちろん行っているが,ではそのほかの部分で,Ivy BridgeはSandy Bridgeとどう違うのか。それを調べてみようというのが本稿のテーマである。
 |
| 4Gamerで独自に入手したCore i7-3770K。性能評価用エンジニアリングサンプルなので,ヒートスプレッダ上の刻印は最終製品と異なる |
 |
| Core i7-2700K/3.5GHz メーカー:Intel 問い合わせ先:パソコンショップ・アーク パソコンショップ・アーク販売価格:2万7200円(※2012年4月24日現在) |
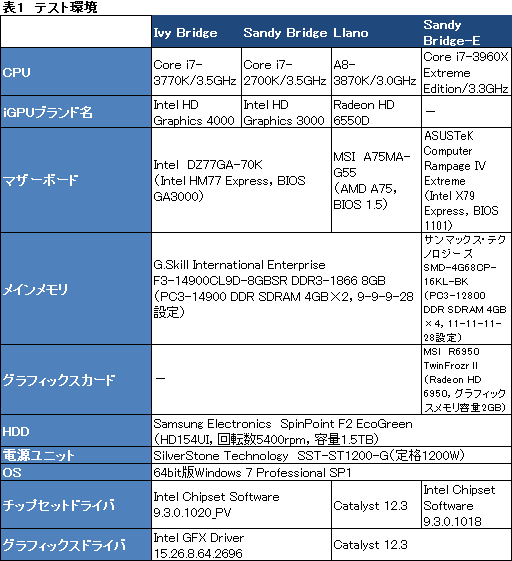
ちなみにいま挙げた3700Kのスペックは,Sandy Bridgeコアを搭載する「Core i7-2700K/3.5GHz」(以下,2700K)と完全に同じ。そこで今回は,秋葉原のPCパーツ&PCショップであるパソコンショップ アークの協力で,2700Kを比較対象として用意した次第だ。また,Core i7-3000番台最上位モデルとしての「Core i7-3960X Extreme Edition/3.3GHz」(以下,3960X)や,iGPUが持つOpenCL性能比較用の「A8-3870K/3.0GHz」(以下,A8-3870K)も揃えている。
CPUクーラーは,3770Kと2700Kが2700Kの製品ボックスに付属のもの,A8-3870Kも製品ボックスに付属のもので,3960Xが空冷タイプのIntel純正品「RTS2011AC」だ。
 |
 |
なお,テスト条件を共通化したこともあって,UEFIやドライバのバージョンは最新版よりも若干古くなっているので,この点はお断りしておきたい。発表直後のチップセットや発売直後のマザーボード用UEFIやドライバが頻繁に更新されるのはやむを得ないのだが,24日の正式発表以降に入手可能なUEFIやドライバで,今回のテスト結果よりも若干高いスコアが得られる可能性はあるだろう。
トランスコード性能などの改善により,PCMark 7では
Ivy BridgeとSandy Bridgeの間でスコア差が生じる
さっそくテストの考察に入っていきたい。
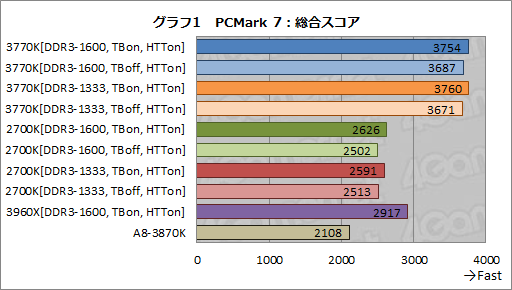
まずは,Futuremark製のPC性能の総合ベンチマークソフト「PCMark 7」(Version 1.0.4)におけるテスト結果からだ。注目したいのはデュアルチャネルDDR3-1600コントローラの効果と,22nmプロセス技術の採用で熱や消費電力周りの余裕が大きくなり,TBの効果が変わるかどうか……だと思っていたのだが,蓋を開けてみると予想外の結果になってしまった。
グラフ1はPCMark 7の総合スコアだ。ここでは3770Kと2700Kでメモリ設定をDDR3-1600とDDR-1333で切り替え(※2700KのDDR3-1600はオーバークロック動作となる),TBの有効/無効も切り替えている。A8-3870Kでは省電力機能である「AMD Cool’n’Quiet Technology」(CnQ)を無効化しているが,ここでは3770Kが,2700Kどころか,6コア12スレッド動作の3960Xすらも大きく上回るスコアを示した。いったいなぜか。
 |
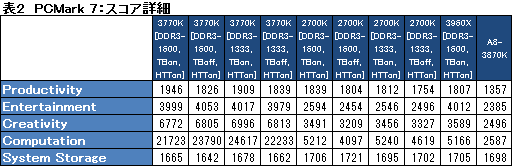
その理由は,スコアの詳細を見ると明らかになる(表2)。3770Kがスコアを伸ばすのは,
- Entertainmentテスト:ビデオ再生&トランスコード性能やストレージ性能,DirectX 9〜10世代の3Dグラフィックス処理性能,Webブラウジング性能などを見るもの
- Creativityテスト:ビデオ編集関連性能や画像処理性能,ビデオの高画質トランスコード性能などを見るもの
- Computation:ビデオのダウンスケールトランスコードや高画質トランスコード性能,画像処理性能を見るもの
の3つで,要するに,ビデオ関連処理が含まれる項目だけ,極端にスコアが上がっているのだ。
 |
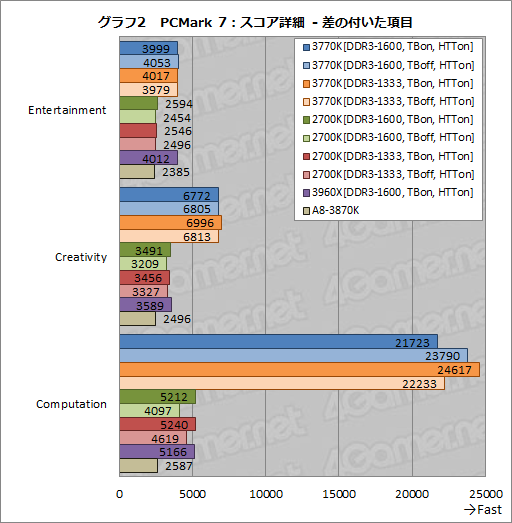
グラフ2は,いま挙げた3テストの結果をグラフ化したものだが,とくにComputationにおける3770Kのスコアが著しく高い。これが,グラフ1における「3770K圧勝」を生んだ主要因と見ていいのではなかろうか。
 |
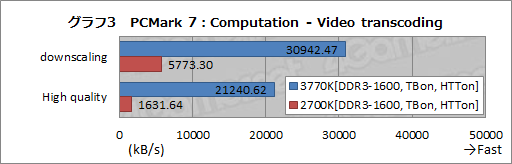
では,Computationテストで何が起こっているのだろう。グラフ3は,本テストに含まれるビデオトランスコード関連の2項目を抜き出してまとめたものだ。ここでは3770Kと2700KをDDR3-1600のTB&HTT有効で比較しているが,ご覧のとおりの大差がついている。
 |
 |
Intelは,Ivy BridgeでQSVが強化され,最大で2倍ものトランスコード性能を持つとしているが,どうやら2倍どころの騒ぎではないケースもあるようだ。
4Gamerで入手したIntelの資料「3rdGen_Intel_Core_Processor_Preliminary_Desktop_Datasheet.pdf」によると,Ivy Bridge世代のQSVではVC-1(WMV)およびMPEG-2エンコードの一部をハードウェアが支援するという記述が見受けられる。
 |
もちろん,3Dグラフィックス関連項目が含まれるEntertainmentテストでは,Ivy Bridge世代で強化されたiGPUの効果も現れている。
グラフ4は,Entertainmentテストに含まれるDirectX 9レンダリングのフレームレートで,ここでは3770Kと2700Kの間に4fps程度の差が出た。こういったGPU性能の違いも,Entertainmentテストのスコアには反映されているわけだ。
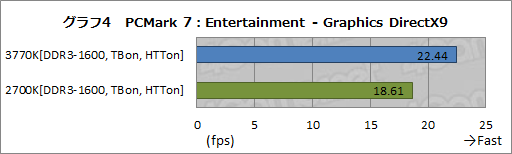 |
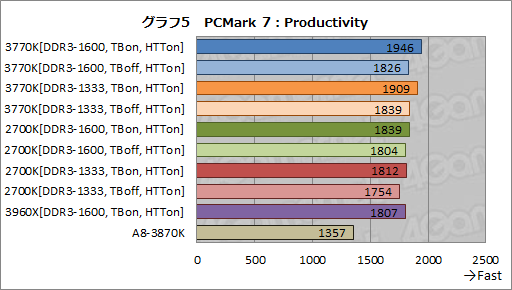
一方,QSVやiGPUの性能がスコアをほとんど左右しないProductivityテストだと,3770Kと2700K感のスコア差はぐっと小さくなる(グラフ5)。ただ,3770Kのほうが2700Kよりも高めのスコアを示すという傾向自体に違いはない。
細かく見てみると,メモリコントローラのDDR3-1600設定とDDR3-1333設定とで,スコアに違いは確かに出ているものの,影響力はそれほど大きくない。対してTBの有効時と無効時で比較すると,3770Kでは約6%,2700Kでは約2%と,3770KのほうがTBの効果が高いと分かる。TBについては別途テストする必要がありそうだ。
 |
いずれにせよ,PCMark 7ではQSVの影響が大きすぎて,CPUコアそのものの性能が分かりにくい印象である。
浮動小数点演算性能に
わずかな改善が見られる3770K
というわけで,ここからはCPUコアそのものの性能を見ていくことにしよう。
ここで用いるのは,PC情報表示&ベンチマークソフト「Sandra 2012」(SP3 Version 18.40)。ここでは,スコアを揺るがす原因となり得るTBおよびHTTを無効化してテストを行っていく。また,Intel Microarchitecture(Sandy Bridge)間の違いに焦点を当てるため,マイクロアーキテクチャの異なるA8-3870Kは比較対象から外している。
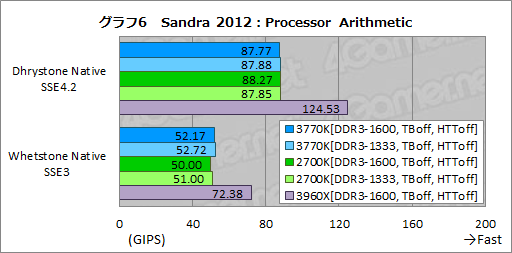
さっそくだが,グラフ6は,SSE命令セットを用いた整数演算および浮動小数点演算の性能を測る「Processor Arithmetic」のスコアだ。コア数の違いによって3960Xが頭一つ飛び抜けていることを除けば,整数演算性能を測る「Dhrystone」,浮動小数点演算性能を測る「Whetstone」とも,3770Kと2700Kの間にスコア差はほとんどない。また,メモリ設定の違いもこのテストでは現れなかった。
 |
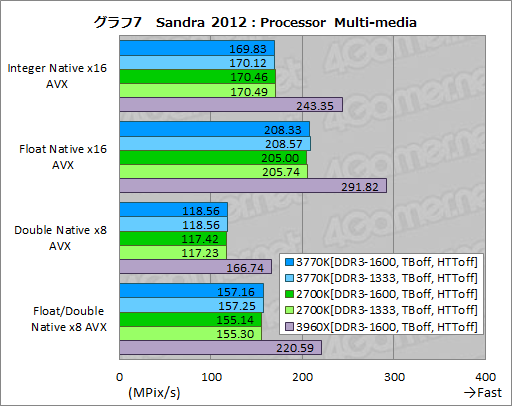
続いてグラフ7は,AVX命令を用いたマルチメディア系演算の性能を見る「Processor Multi-media」の実行結果である。このテストでも3960Xは頭一つ抜け出している。
3770Kと2700Kの比較では,AVXの整数演算性能を見る「Integer Native 16 AVX」でほぼ横並びとなった一方,32bit単精度浮動小数点演算性能を見る「Float Native x16 AVX」と64bit倍精度浮動小数点演算性能を見る「Double native x8 AVX」,そして単精度と倍精度混在の浮動小数点演算性能を見る「Float/Double Natvie x8 AVX」で,わずかながら3770Kが2700Kを上回るスコアを示した点に注目したい。
いずれもスコア差は非常に小さいものの,同じマザーボード&UEFI設定で3つのテストが同じ傾向を示すとなると,偶然や測定誤差が生じたとは考えにくいところだ。AVX命令の浮動小数点演算周りには何からの改良が加えられた可能性がありそうである。
 |
グラフ8は暗号化の性能を見る「Cryptography」の結果だ。
AES(Advanced Encryption Standard)256bitのエンコード/デコードを行う「Encryption/Decryption Bandwidth AES256-ECB AES」に向けては,Sandy Bridgeコアでアクセラレータが組み込まれたため,非常に高いスループットが得られるようになっており,それだけにDDR3-1600設定もかなり効いている印象だ。ただ,3770Kと2700Kの間に大きな違いはないようにも見える。
一方,CPUべースのアクセラレーションがない「SHA2」(Secure Hash Algorithm 2)を用いたハッシュの計算だとスループットはぐっと下がり,メモリ設定の違いも目立たなくなっている。3770Kのほうが2700Kよりも若干高いスコアを示しているものの,このテストだけで理由を求めるのは難しい。
 |
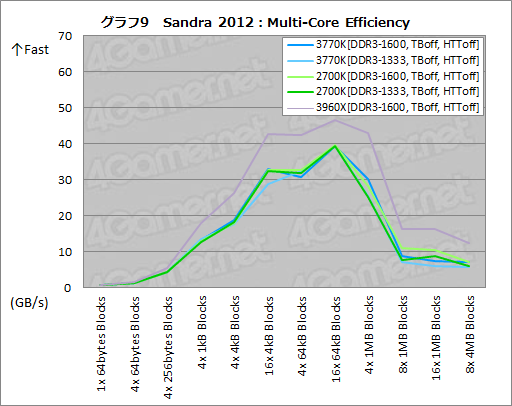
少し視点を変えて,グラフ9は,コア間のデータ転送レートを見る「Multi-Core Efficiency」のテスト結果となる。
CPUコアとキャッシュを結ぶリングバスが二重化されている3960Xが抜けたスコアを示すのは当然として,3770Kと2700Kの間にこれといった違いはない気配が感じられる(※3770KのDDR3-1333設定で「16x4kB Blocks」の帯域幅がやや落ちているが,DDR3-1600だとそうなっていないので,おそらく測定誤差だろう)。
LLCまでのキャッシュから外れる「16x1MB Blocks」では2700Kのスコアがやや高めだが,このあたりはメインメモリの帯域幅と合わせてチェックする必要がありそうだ。
 |
グラフ10はiGPUのシェーダコアが持つグラフィックス性能を見る「Video Rendering」だ。iGPUを持たない3960Xを除いて,3770Kと2700Kの直接比較を行った結果である。
iGPUの3D性能はレビュー記事のGPUコア編をチェックしてもらえればと思うが,単純なレンダリング性能比較だけでも,3770Kが2700K比で大幅な性能向上を実現したことは見て取れるだろう。とくに倍精度の演算を見る「Native Double Shaders」で約4倍というスコア差を示しているのは目を引く。
3770Kと2700KのiGPUを比較すると,「Execution Unit」(以下,実行ユニット)数が順に16基,12基。最大動作クロックは順に1.15GHz,1.35GHzなので,正直,このスペックだけでは説明できない。実行ユニットの増強に合わせて,実行ユニットの使い方そのものにも改良があったと見るべきだろう。
 |
次にグラフ11は,ビデオファイルをH.264フォーマットへ変換するときの性能を見る「Video Transcode」である。
ここでは2つのテスト項目が用意されているが,いずれもQSVで対応するH.264形式へのトランスコードということもあり,QSVの強化分,3770Kのほうが高いスコアを示しているのが分かる。
面白いのは,3770Kでのみ,DDR3-1600設定とDDR3-1333設定でスコアに有意な違いを確認できること。QSVは固定ハードウェアで,しかもスペックの詳細が明らかになっていないため,内情は分からないのだが,少なくとも3770KでメモリクロックがQSVの性能に影響を及ぼす「ことがある」のは,意識しておいていいかもしれない。
 |
グラフィックスメモリのバス帯域幅を見る「Video Memory Bandwidth」だと,3770Kで,グラフィックスメモリ周りに大きな改善があるのを見て取れた(グラフ12)。
「Internal Memory Bandwidth」はGPU側グラフィックスメモリ内部でGPUにデータ転送を行わせたとき,「Interface Transfer Bandwidth」はCPUかDMA(Direct Memory Access)でメインメモリからグラフィックスメモリへデータ転送を行わせたときの結果になるが,ローカルに専用のグラフィックスメモリを持たない3770Kの場合,いずれのテストでもメモリコントローラは性能を大きく左右することになる。そして実際,3770KにおけるDDR3-1600設定時のスコアはDDR3-1333設定に対してInternal Memory Bandwidthで約28%,Interface Transfer Bandwidthで約27%高い。
iGPU内の実行ユニット数がSandy Bridge時代よりも増えた3770Kでは,よりメモリが“効く”ようになっている気配だ。
 |
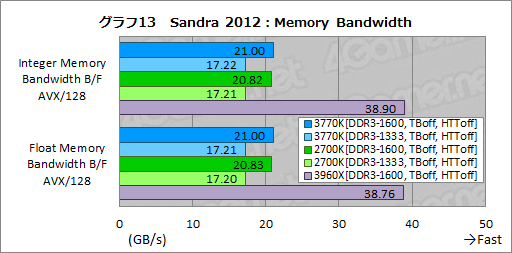
同じメモリでも,グラフ13の「Memory Bandwidth」はメインメモリの帯域幅を見るテストである。当然のことながら,ここでもクアッドチャネルメモリアクセスを実現した3960Xのスコアが群を抜いているが,3770Kと2700Kでは,ほぼ横並びと述べていいスコアにまとまっている。DDR3-1600とDDR3-1333の設定を変更したときのスコア差もほぼない。
Multi-Core Efficiencyのテスト結果で,キャッシュから外れる領域において3770Kと2700Kでは帯域幅の違いが見られたが,少なくともメインメモリの帯域幅に違いはないようだ。Multi-Core Efficiencyのスコア差はLLCや内部リングバスの効率といった,別の原因によるものかもしれない。
 |
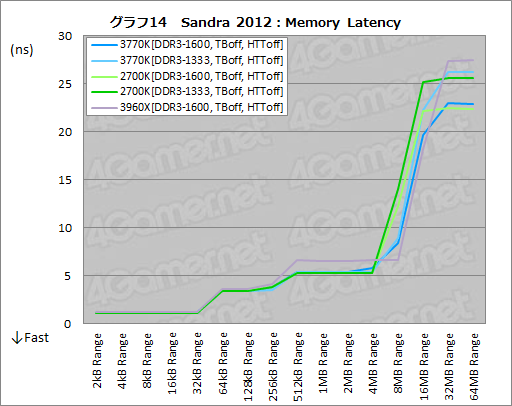
グラフ14の「Memory Latency」はメモリ周りのレイテンシを見たものだ。テストに用いたメモリモジュールと接続チャネル数の異なる3960Xだけ異なる傾向が現れるのは当然なので,ひとまずこんな感じだと理解しておけばいいだろう。
3770Kと2700Kの間では,LLCの容量ギリギリとなる「8MB Range」で3770Kのレイテンシが明らかに低く,ここが目立った違いになっている。上のグラフ13のところで筆者はLLCや内部リングバスに手が入った可能性を指摘したが,ここでの結果はそれを補強するものということになりそうだ。
 |
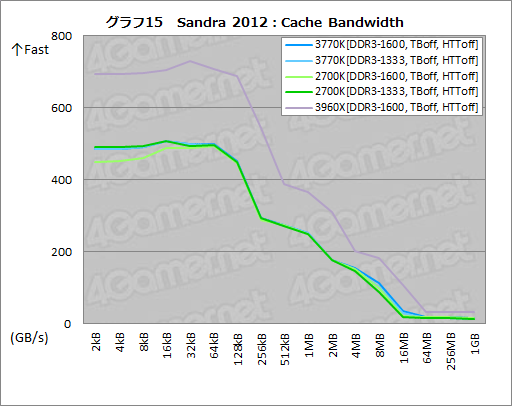
Sandra 2012を用いたテストでは最後となるのがグラフ15の「Cache Bandwidth」で,内部のリングバスが二重化されている3960Xだとキャッシュがヒットする領域で抜けたスコアを示すものの,3770Kと2700Kの間に目立った違いは見られない。あえていえば,2700KのDDR3-1600設定時に2kB〜16kBの間が落ち込んでいるのが気になるものの,DDR3-1333設定では見られないので,測定誤差と見ていいと思われる。
 |
以上の結果から,「3770Kと2700KのCPUコアに,大きな性能の違いはないようだが,LLCか内部リングバス,あるいは両方に若干の改良が加えられてた可能性は指摘できる」と言えそうだ。また,浮動小数点演算周りにも何らかの改良が行われた可能性はあるが,いずれにせよ,両者の違いは非常に小さいという結論になりそうだ。
AIDA64でも,演算性能に
わずかな違いを確認
Sandra 2012で見られた違いは何なのか。追試のために,Sandra 2012と似たようなシステム情報表示&ベンチマークツールである「AIDA64」(Version 2.30.1904)の結果も見てみることにしよう。テスト設定はSandra 2012と同じだ。
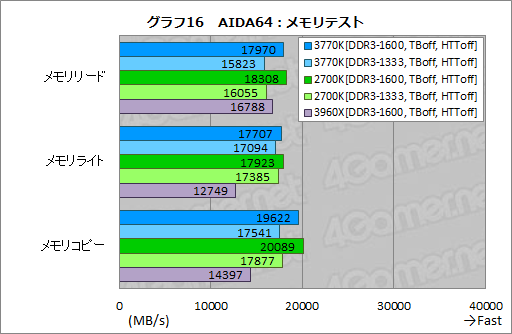
まずグラフ16は,AIDA64のメモリテスト結果をまとめたもの。Sandra 2012と異なり,AIDA64ではデュアルチャネル分のスコアが取得されるため,クアッドチャネルメモリアクセスの3960Xではスコアが2分の1になったりしている。
というわけで3770Kと2700Kを比較してみると,2700Kのスコアがわずかながら3770Kよりも高い。先に示した,Sandra 2012 SP3におけるメモリ周りのテストと合わせて考えると,同じ設定を行ったときのメモリコントローラ性能がIvy Bridge世代で高くなったということはなさそうだ。
 |
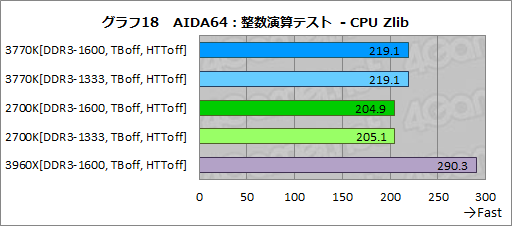
整数演算のテストでは,ハッシュの計算を行う「CPU Hash」と,データ圧縮を行う「CPU Zlib」とで優位なスコア差が見られた(グラフ17,18)。
CPU HashとCPU Zlibはいずれもマルチスレッド化されており,今日(こんにち)のCPUにとってさほど負荷の高い処理ではない。負荷の低いなかでスコアに違いの生じたところからすると,Sandra 2012のテストで確認されたLLCか内部リングバスの効率の違いが出た可能性はあるだろう。
 |
 |
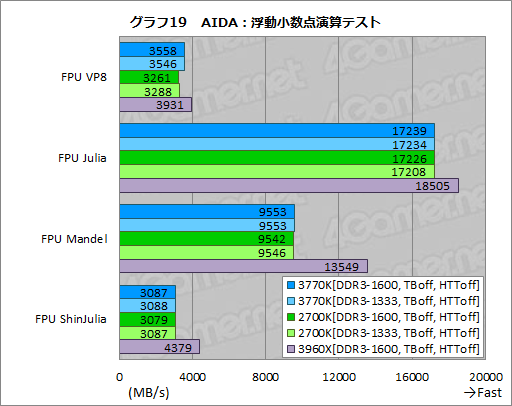
一方,Sandra 2012だと複数のテスト項目で違いを確認できた浮動小数点演算テストは,AIDA64だと「FPU VP8」でのみ違いが確認できるという結果になった(グラフ19)。
FPU VP8は,Googleの提唱するオープンな動画フォーマットであるVP8のエンコード性能を測るものだが,VP8形式のエンコードはもちろんQSVのサポート対象にはなっていない。また,ソースとなる動画フレームは(単精度浮動小数点演算を使って,マンデルブロ集合の一種であるジュリア集合を実行するテスト)「FPU Julia」で生成したものが使用されるとのことなので,ビデオのデコード性能もベンチマークスコアは左右していないはずだ。さらに言うなら,FPU Juliaのスコアに大きな違いはない。
以上のことから,Sandra 2012で確認できた浮動小数点演算性能のわずかな差が,FPU VP8でも現れたという見方ができるのではないかと考えている。
 |
Sandra 2012とAIDA64のテスト結果を見る限り,「3770Kと2700Kの間に演算性能の違いは確実にあるが,それは極めて小さい」と判断してよさそうだ。
Ivy BridgeのiGPUで
GPGPUは使えるのか
冒頭でも述べたが,Ivy BridgeコアのiGPUでは,Intel製GPUとして初めてGPGPUの機能,具体的には,Microsoftの提唱するDirectComputeと,Khronos Groupが策定したGPGPU向け言語仕様であるOpenCL(Version 1.1)が利用できるようになっている。
DirectComputeもOpenCLも,コンシューマ向けPC市場で積極的に利用されているとはあまり言えないものの,対応アプリケーションが徐々に増えているのは確かなだけに,Intel製iGPUのGPGPU対応能力はチェックしておいたほうがよさそうだ。
ただ,最初に断っておくと,原稿執筆時点で,Ivy BridgeコアのGPGPUサポートはまだ完全とはいえないようである。DirectX 11に含まれるDirectComputeはほぼ問題なく利用できるようだが,OpenCLではAMDやNVIDIAのGPUだとサポートされる拡張仕様のいくつかがサポートされておらず,世の中に出回っているOpenCLアプリケーションのすべてが使える状況にはなっていなかったからだ。
今後,ドライバのアップデートによって改善していく可能性はあるが,OpenCL対応が限定的であるということは押さえておいたほうがいいだろう。
さて,本稿では動作させることのできたベンチマークソフトを用いて3770KのGPU性能を見ていきたいと思うが,そもそもiGPUを持たない3960Xと,GPGPUをサポートしない2700Kは比較対象として使えない。冒頭でも述べたとおり,ここではA8-3870Kが比較対象となる。
テスト時のメモリ設定は,3770K,A8-3870KともDDR-1600。3770KではTB,HTTともに有効とし,A8-3870KはCnQを無効化している。いずれのCPUでも,性能を最も引き出せると考えられる状態にしてあるとイメージしてもらえれば幸いだ。
 |
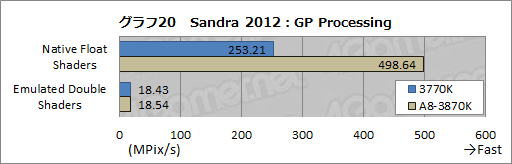
グラフ20は,OpenCLを用いて単精度浮動小数点演算と倍精度浮動小数点演算を行うときの性能を見る「GP Processing」の結果をまとめたものだ。単精度の「Native Float Shaders」ではA8-3870Kが圧勝だが,倍精度を用いる「Emulate Double Shaders」だと両者の違いがほとんどなくなっており,興味深い。
A8-3870Kで集積される400基のGPUコアには「Radeon HD 6550D」というブランド名が与えられているが,その実,ATI Radeon HD 5500/5600シリーズの「Redwood」コアをベースとした簡略版で,倍精度はエミュレーションのみとされている。一方,3770KのiGPUはグラフ10のVideo Renderingテストでも倍精度でそこそこのスコアを見せていたので,僅差という結果になったのだろう。
 |
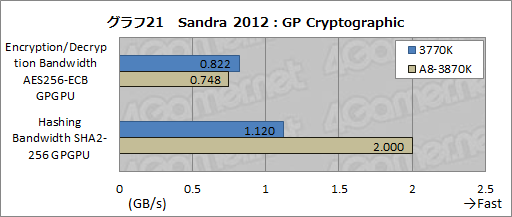
OpenCLを使って暗号化の処理を行う「GP Cryptographic」の結果をまとめたものがグラフ21だ。AES 256bit暗号のエンコード/デコードを行うテスト「Encryption/Decryption Bandwidth AES256-ECB GPGPU」と,SHA2によるハッシュの計算テスト「Hashing Bandwidth SHA2-256 GPGPU」という2種類があり,いずれも整数演算が主体になる。
結果を見ると,前者はA8-3870Kにあまり適した処理ではないようで,3770Kのほうがむしろやや高いスコアを示した。ただ,SHA2の計算はダブルスコアでA8-3870Kの完勝だ。
むしろここで注目すべきはA8-3870(というよりATI Radeon HD 5000シリーズのGPUコア)で,処理するアルゴリズムによって得意不得意の差が大きく出ていることだったりもするのだが,その点は後述したい。
 |
グラフ22は,OpenCLのコードを用いてメモリバス帯域幅をテストする,つまりGPGPUにおけるメモリ帯域幅を調べる「GP Memory Bandwidth」の結果である。
GPU内部の転送レートを見る「Internal Memory Bandwidth」では,A8-3870が高いスコアを示した。3770KでもGPUのメモリ周りが強化されていることは先に触れたとおりだが,この部分ではAMDに一日の長があるようだ。
CPUからGPUへのデータ転送時におけるメモリバス帯域幅を見る「Interface Transfer Bandwidth」だと2製品のスコア差はほとんどないが,
- iGPUの場合,(ローカルフレームバッファが用意されない限り)グラフィックスメモリ=メインメモリとなる
- メインメモリのアクセス設定は2製品ともデュアルチャネルDDR3-1600
なので,この結果は納得できるところである。
 |
 |
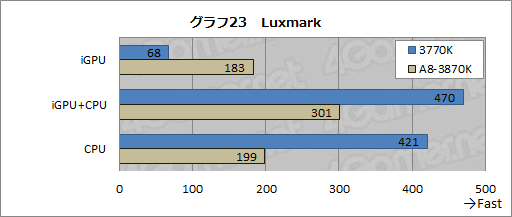
Luxmarkというのは,レイトレーシングを用いて3Dグラフィックスのレンダリングを行うフリーのレンダリングエンジン「Lux Renderをベースに,性能測定用のデータとスクリプトをセットにしたベンチマークスイートのこと。OpenCLに対応しており,GPUのみやCPUのみ,あるいはGPUとCPUの両方を同時に用いたときの描画性能,具体的にはレイトレーシングにおけるレイの計算速度を見ることができる。
そんなLuxmarkを用い,3770KとA8-3870Kのスコアを比較したものがグラフ23だ。Luxmarkのスコアは単に「Result」となっているだけなので分かりにくいが,数字の大きいほうがよいスコアという理解でいい。
iGPUのみを用いたテストでは,A8-3870Kが3770Kに約2.7倍の差を付けるのに対し,iGPUとCPUの両方を用いたテストだと,3770Kが逆に対A8-3870Kで約1.6倍のスコアを叩き出しているのが,ここでの見どころだ。
その原因はCPUのみを用いたスコアで一目瞭然だろう。CPUのみを用いたときは,3770Kが対A8-3870で約2.1倍のスコアを示しているため,両方を使うと3770Kの圧勝に終わるというわけだ。
もっとも,それだけが原因ではない気配もある。もったいぶって恐縮だが,これも後述とさせてほしい。
 |
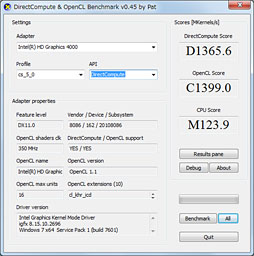 |
このテストは,「演算」を用いて,1秒あたりに実行できるGPUのカーネル(=GPUで実行できるプログラムの最小単位)数を測定するものになっている。「演算」の詳細説明は見当たらないのだが,ごく小さな規模の処理を繰り返しすような形になっているようである。得られるスコアは1秒あたりに実行したカーネル数だ。
本ベンチマークはその名から想像できるように,DirectComputeとOpenCLの双方でテストできるため,今回はそれぞれの結果をグラフ24に示してみたが,ここではテスト条件にかかわらずA8-3870Kのスコアが高いのが分かるだろう。
 |
 |
| LlanoのiGPUにおけるブロック図 |
 |
| Ivy BridgeのiGPU概要 |
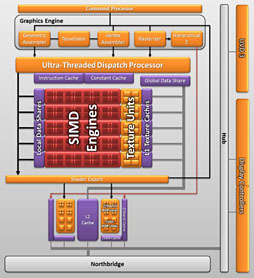
Radeon HD 6550Dと名付けられたA8-3870KのiGPUは400基のシェーダプロセッサ(以下,SP)を持つとされるが,実際には,5基のSPをひとまとめにして「Thread Processor」(以下,TP)とし,さらにTPを16基束ねてテクスチャユニットなどと組み合わせ,「SIMD Engine」とする構成になっている。1 SIMD Engine=16 TP=80 SPであり,A8-3870Kとしては5基のSIMD Engineを持っている計算になるわけだ。
OpenCLはSIMD Engineを1基のプロセッサとしてカウントするため,A8-3870KのiGPUは5基のプロセッサということになる。1つのプロセッサ(=SIMD Engine)で同じカーネルを16個同時に実行できるから,5基のSIMD Engineで合計80個のカーネルを実行できるということになる。
一方の3770Kだと実行ユニットは16基で,1基あたり1個のカーネルを実行可能。つまり,1度に実行できるカーネル数はシンプルに16である。
……と,ここまで説明するともうお分かりだろう。
扱えるカーネル数がスコアにそのまま反映されるDirectCompute & OpenCL Benchmarkでは,A8-3870Kが圧倒的に有利なのだ。
 |
その名から想像できるとおり,nqueen_clは,整数演算を駆使する古典的な問題「N-Queen問題」(※碁盤目状となるn×nのボードに,縦横斜めに移動できるチェスのクイーンn個を互いに攻撃できないよう配置するパターンがいくつあるかを求める問題)をOpenCLで実装したもので,ソースコード一式も添付されている。
コマンドラインから実行するシンプルなベンチマークなので派手さはないが,GPUの整数演算性能を見るのには役立ちそうということで取りあげる次第だ。
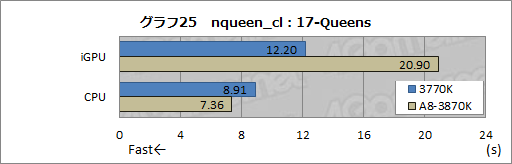
今回は,比較的,実行しやすく比較しやすい時間で処理が終わる17-Queensの処理時間を見ることにし,テスト結果をグラフ25まとめたが,所要時間を見ると,iGPU実行時に3770K,CPU実行時にA8-3870Kのほうが速いという,これまでとは完全に逆のスコアが出てしまった。
 |
これは驚きの結果といえるが,もちろん理由がある。
DirectCompute & OpenCL Benchmarkのところで説明したとおり,A8-3870Kで異なるカーネルを実行できるSIMD Engineの数は5基である。SIMD Engineを構成する16基のTP(≒80基のSP)を効率的に利用できればA8-3870Kがもちろん有利なのだが,nqueen_clではうまく活用できていない――これはnqueen_clの処理の内容と作り方によるところが大きい――ようだ。
そのため,むしろ16基の実行ユニットにN-Queen問題の探索コードを分散できる3770Kが優位な結果に終わったというわけである。
もう1つ興味深いのは,CPUコアに実行させたとき,むしろA8-3870Kのスコアが3770Kよりも高くなるところだ。
今回はCPUコアで実行させるのにあたって,OpenCLコードをCPUのコードに変換するnqueen_clの「-cpucl」オプションを利用した。A8-3870Kのスコアが3770Kよりも高くなったのは,OpenCLコードをCPUコードに変換するコンパイラの効率でAMDに分があるためという可能性がありそうだ。
なお,原稿執筆時点において,3770KではOpenCLの外部変数(Atomics)拡張機能が完全にはサポートされていないため,3770Kではnqeen_cl実行時に外部変数を使わない「-noatomics」オプションを付ける必要があった。この問題はドライバのアップデートで解決するかもしれないが,ひとまず事実として書き記しておきたい。
……以上のテスト結果から,3770KのGPGPU機能はあくまでもオマケ的な存在だということになるだろう。総合的に見ればA8-3870Kに対して勝ったり負けたりといったところなのだが,勝ち方や負け方が極端すぎるのが気になる。もっといえば,倍精度浮動小数点演算がエミュレーションになる時点で,Llanoコアを採用するA8-3870KのGPGPU機能もオマケのようなものなので,「実用的な機能かというと疑問が残る」という意味ではいい勝負といったところなのだが。
ただ,少なくとも互換性が維持され,DirectComputeやOpenCLを用いたアプリケーションをiGPU側で実行できるレベルに達しているという意味では,価値があると言っていいようにも思う。
TBの挙動でSandy Bridgeとの間に
目立った違いは見られない
PCMark 7におけるProductivityテストの結果を示したグラフ5だと,3770Kのほうが2700KよりもTB有効時のスコアがやや高く出ていた。22nmプロセスの採用で熱的,消費電力的ヘッドルームが大きくなり,TBの効果が出やすくなったというのはあり得る仮定だろう。ここからはそのあたりをチェックしてみたい。
TBのクロック推移を記録するツールとして有名なものには,CPU-Zが配布している「TMonitor」があるのだが,テスト開始時点の最新版となるバージョン1.03ではIvy Bridgeコアに非対応で動作しない。そのため,今回は筆者自作のツールを用いることにした。
まず,基本的なブーストのかかり方を,これまた自作ツールでコアごとに負荷をかけながらクロックを記録するという方法で見てみよう。
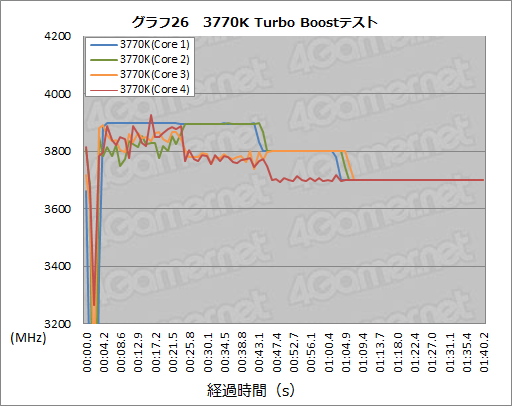
今回は,最初の20秒はCPUの1コアのみ負荷をかけ,以後,きっかり20秒ごとに,1・2コア,1〜3コア,1〜4コアといった具合で「負荷をかけるコアの数」を自動的に変更していくという手法をとることにした。そして,3770Kでそのテストを行ったときの結果がグラフ26だ。
1つのコアのみに負荷をかけると,他のコアも引きずられてクロックが上昇するものの,3.9GHzに張り付くのは当該の1コアのみ。続いて2つのコアに負荷をかけると2コアだけが3.9GHzへ張り付くようになり,3つのコアに負荷がかかると3.8GHzに張り付く。そして,全コアに負荷がかかる3.7GHzに張り付くという,仕様どおりの挙動を示すのが分かるだろう。
 |
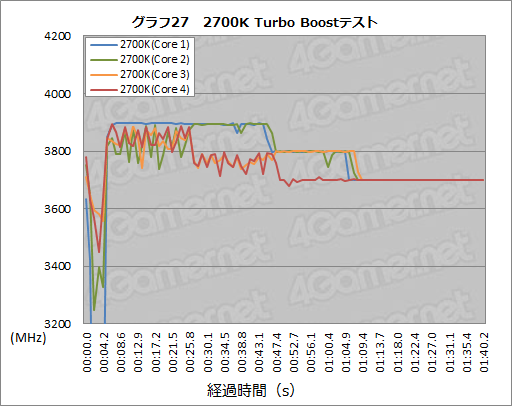
ちなみにTBの基本的な挙動は2700Kでも変わらない。同じツール,同じ手法で2700Kに負荷をかけていったときの結果がグラフ27だが,ほぼ相似形と述べていい。
ただ,まったく同じというわけではないようだ。まず,1コアに負荷をかけ始めてから,最大の3.9GHz付近にまでクロックが立ち上がる速度は,2700Kより3770Kのほうが1秒程度速い。クロックの立ち上がりは,3770Kのほうが2700Kより速いのである。
また,2コア以上に負荷をかけた時の平均的なクロックを見ると,わずかながら3770Kのほうが高く,上限にしっかり張り付いているといった違いもあるようだ。
 |
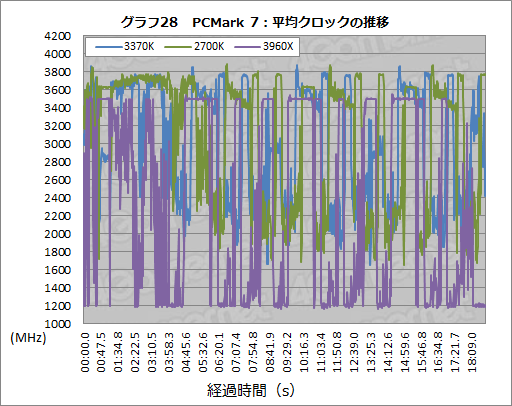
では実アプリケーションだとどうだろうか。PCMark 7で総合スコアを取得するためのテストを通しで実行し,その間のクロック推移を追った結果がグラフ28となる。
ここでは3770Kと2700K,3960Xの3製品でそれぞれ搭載される全CPUコアの平均クロック推移を追ったものだ(※各コアを個別に入れると何が何だか分からなくなるため平均とした)。
ベンチマーク進行に要する時間がCPUによって異なるため,グラフは完全な同一の形状にはならないのだが,それでも,3770Kと2700Kの間にさほど大きな違いが見られないことは見て取れるだろう。実のところ,時間で平均を取ると2700Kのほうが3770Kよりもクロックは高かったりするので,PCMark 7で見る限り「22nmプロセス技術を採用して製造される3770Kのほうが高クロックになりやすい」という事態にはなっていないようだ。
 |
ならばなぜProductivityテストで3770Kのスコアが2700Kを上回ったのか。
1つ要因として考えられるのは,グラフ26,27で確認したクロックの立ち上がり方や,高クロック時の安定性の違いだろう。3770Kのほうがクロックの立ち上がりが速く,またTB時のブーストクロックも安定しているので,それがスコアに寄与した可能性はある。こうした違いは実アプリケーションを前にしたクロック推移では確認しづらいので,時間平均のクロックが低かったとしても,クロックの立ち上がりが速ければ,最終的なスコアが高くなっても不思議ではない。
そのほか,先に改善の気配が見られたLLCやリングバスの改善もクロックが高いほど効果が大きくなると考えられるので,TBでブーストしたときの性能が伸びやすいといったことがあるのかもしれない。
なお,上のグラフ28では3960Xのクロック推移も示しているが,これは純粋に筆者が挙動を確認したかっただけだったりもする。さすがに6コアだと熱的,消費電力的に厳しいようで,テストを通じ,平均動作クロックは3.5GHz程度で頭打ちになっている。3960Xはクロックでなく,コア数で稼ぐ設計のCPUというわけである。
ところで,先のGPGPUテストにおいて,3770KのGPGPU処理が本当にGPUで実行されているのか疑問を感じた人はいるかもしれない。
DirectComputeやOpenCLのコードをCPUコードへ変換して実行するのはもちろん可能であり,また,IntelはSandy Bridge以前のiGPUでグラフィックス処理の一部をCPUコアに肩代わりさせていた前歴もあったりするので,GPGPU処理の一部,もしくはかなりの部分をCPUコア側で実行しているのではないかと勘ぐる向きがあっても不思議はない。
というわけで,Luxmark実行時のCPUクロックの推移も記録してみることにした。
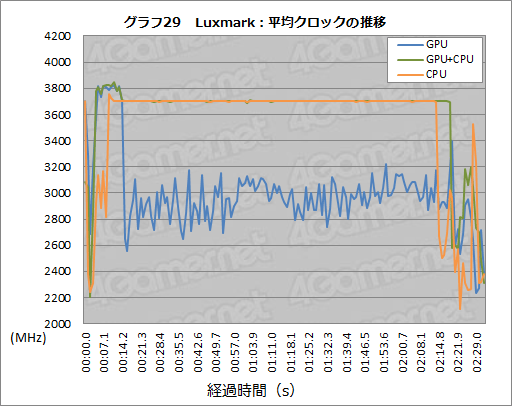
グラフ29は,3770KのiGPUのみ,iGPUとCPU,CPUのみを使ってそれぞれLuxmarkを実行し,そのときのCPU平均クロック推移を追ったものになる。ご覧のとおり,iGPUで実行したときはCPUの平均クロックが3GHz前後に落ち,CPUに処理を行わせたときには3.7GHzに張り付いている。
つまり,iGPUで実行させたときのCPU負荷は,CPUで処理させたときと比べて明らかに低いわけだ。もちろん,iGPUで処理のすべてを行っているかどうかは断言できないが,後述する消費電力のテスト結果と併せて考えれば,OpenCLコードの大部分はiGPU側で処理されていると判断していいように思われる。
 |
ピーク消費電力は
大幅に低減
ゲームアプリケーション実行時の消費電力はレビュー記事のほうで紹介しているが,ここではPCMark 7実行時とLuxmark実行時の消費電力を見てみることにしよう。今回は単体GPUが必要となる3960Xを除く3製品で比較する。
テストに用いたのは,ログが記録できるワットチェッカー「Watts up? PRO」。OSの起動後30分間操作せずに放置した時点を「アイドル時」,テスト時に最も高い消費電力を示した時点を,テストごとの実行時としている。
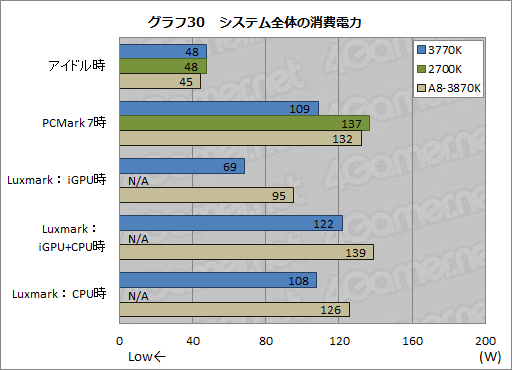
その結果をまとめたものがグラフ30だが,アイドル時の消費電力で3770Kと2700K,A8-3870Kの間に違いはほとんどない。
一方,PCMark 7実行時は,3770Kが2700Kと比べて18Wも低い。マザーボードなど,ほかの使用機器が完全に同じなので,CPUだけで18W低減したわけだ。
 |
iGPUとCPUの双方に高い負荷をかけるという,従来型のベンチマークテストではできないような負荷のかけ方ができる,Luxmark実行時の消費電力も興味深い。
GPGPUをサポートしない2700KのスコアはN/Aとなるが,3770KはiGPUだけを用いたとき69Wに留まり,CPUのみのときには108W,iGPUとCPUを併用すると122Wまで伸びていることが分かる。CPUだけを使ったときとiGPUとCPUの両方を使ったときのスコア差は14Wだが,アイドル時とiGPUのみを使ったときのスコア差が20Wあるので,iGPU利用時と,iGPU+CPU利用時とでは,熱設計枠か消費電力枠のいずれかで性能にブレーキがかけられていると推測できる。
そんなブレーキがさらに極端なのがA8-3870Kだ。
A8-3870KではiGPU利用時に95W,iGPU+CPU利用時に139W,CPU利用時に126Wなので,iGPUとCPUとの両方に高負荷がかかると,熱設計枠の制限から性能を抑えざるを得ない状況が発生しているわけだ。A8-3870KのLuxmarkにおいてiGPU+CPU実行時のスコアがあまり振るわなかった原因の1つは,熱設計枠で性能が抑えられたことにありそうな気配である。
CPU性能はほとんど変わっていないが
それ以外は順当に進化したIvy Bridge
 |
iGPUも大幅な性能向上を果たしているが,3Dグラフィックス性能はレビュー記事のとおりで,GPGPUもオマケレベルを超えないため,ゲーマーが積極的に使うようなものではないだろう。QSVが進化しているのは,プレイムービーを手軽にトランスコードして動画共有サイトにアップロードしたいというニーズからすると歓迎できるかも,といったところだろうか。
そのほかにも,Ivy Bridgeではテスト結果に表れづらい改良が施されている。なかでも面白いのが「割り込みが,省電力ステートに落ちていないコアにルーティングされる」よう,改良されている点だ。
たとえばキーを押したとかマウスを動かしたときに割り込みは発生するが,その割り込みが省電力ステートに落ちているコアにルーティングされると,コアが省電力ステートから復帰するまでのラグタイムが生じる。省電力に落ちていないコアに割り振ればラグが減るから,システム全体のレスポンスはよくなるわけである。
この改善は,使ったときの微妙なレスポンスの違いとして体感できることもあるはずで,個人的には,なんとなく3770Kのほうが快適度は高かったような気はする(※もちろん気のせいかもしれないが)。コアがアイドル状態にまず落ちないベンチマークテストでは確認できないのだが,興味深い改良ではある。
そういうわけで,すでにSandy Bridge世代のゲームPCを持っているなら,Ivy Bridgeにわざわざ買い換える必要はないだろう。ただ,Tick製品として順当に進化しているのは間違いないので,これから買うならIvy Bridgeを選んだほうがいいとは言えそうだ。
Intel,「Ivy Bridge」こと第3世代Coreプロセッサを発表
Ivy Bridge「Core i7-3770K」レビュー,CPUコア編。Sandy Bridgeからの性能向上はわずかながら,消費電力の改善は目を引く
Ivy Bridge「Core i7-3770K」レビュー,GPUコア編。3D性能は「Llanoまであと一歩」に迫る
- 関連タイトル:
 Core i7・i5・i3-3000番台(Ivy Bridge)
Core i7・i5・i3-3000番台(Ivy Bridge) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー