










テストレポート
「Core i7」基礎テストレポート。Core 2とは何が違うのかをねちねちと検証する
 |
→Core i7の概要紹介記事
→Core i7のレビュー記事
MSI製のX58マザーボード「ECLIPSE SLI」を利用
メインメモリにはあえてPC3-10600を用意
テストへ入る前に,システムのセットアップを確認しておこう。用いたCPUは,Core i7のトップモデルである「Core i7 965 Extreme Edition/3.20GHz」(以下,Core i7 965)。組み合わせる「Intel X58 Express」(以下,X58)チップセット搭載マザーボードとしては,MSI製「ECLIPSE SLI」の開発途上版サンプルを用意した。
 |
 |
ECLIPSE SLIでは,1デバイス当たり40Aの電流供給能力を持つ,ルネサステクノロジ製の「R2J20602」6基をCPU用として搭載。240Aという,余裕の構成だ。また,その近くにはメモリコントローラおよびQPI用,X58ノースブリッジ用にそれぞれ2基ずつ用意されるが,これら計10基のDriver-MOSFET用に取り付けられたパッシブクーラーは,上位モデルのマザーボードらしからぬ小ささ。DrMOSの低発熱仕様が窺えるものとなっている。
 |
 |
 |
 |
 拡張スロットはPCI Express(以下,PCIe) x16 ×3,PCIe x1 ×2,PCI×2。NVIDIA SLIとATI CrossFireX両対応だ。写真右端には,電源&リセットボタンや,簡易オーバークロック機能を提供するディップスイッチも見える |
 I/Oインタフェース群。別途「Sound Blaster X-Fi Xtreme Audio」相当の機能を提供するサウンドカードが付属するため,サウンド関連の端子は省かれ,代わりにUSBコネクタ×8を用意。CMOSクリアスイッチを持つのも特徴だ |
 |
 |
比較対象としては,DDR3メモリを利用可能なMSI製の「Intel P45 Express」マザーボード「P45 Diamond」を用意。これに,「Core 2 Extreme QX9650/3GHz」を差し,Core i7 965と動作クロックを揃えるべく,オーバークロックで「Core 2 Extreme QX9770/3.20GHz」(以下,C2E QX9770)相当で動作させることにした。メモリモジュールはDDR3-1600動作が可能な,いわゆるオーバークロック品を組み合わせて,こちらも7-7-7-18のレイテンシ設定を行った。
 |
キャッシュ構成の違いが与える影響は?
テストに入っていこう。
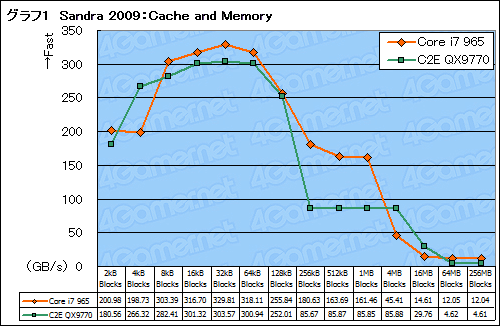
Core i7とCore 2との大きな違いの一つがキャッシュの構成だ。容量も違えば構成も異なることは,別記事で説明しているとおりだが,これがどのような違いになって現れるのだろうか。まずはシステム情報表示ツール兼ベンチマークツールである「Sandra 2009」(Version 15.42)から,CPUのキャッシュとメモリ周りの性能を見る「Cache and Memory」を,実行してみた。
その結果がグラフ1だが,ここで早くも,非常に特徴的なデータが得られている。1MB以下のファイルサイズではCore i7が優秀な転送速度を見せている(※ただし4kBでやや落ち込む理由は分からない)。
Core i7のL2キャッシュは,コアごとに256kBとなっているが,L2の“守備範囲”を超えたサイズでも高い転送速度が見られる以上,CPUコアから見たL3キャッシュの転送レートは相応に高いと見てよさそうである。
一方,L3キャッシュ容量が8MBという事実を踏まえるに,4MBのスコアはもう少し高くてもいいように思える。4MBのデータサイズでは,キャッシュの利きづらい状況が発生しているのかもしれない。
 |
続いては,同じくSandra 2009から,コア間の転送レートを見る「Multi-Core Efficiency」だ。Multi-Core Efficiencyは,コア間で1kB〜128kBのメモリブロックをやり取りし,その速度を計測するテスト。それなりの転送速度を持つL3キャッシュが有効に機能するなら,ここでも高いスコアが出そうだが,グラフ2にまとめたとおり,Core i7は,2x128kBまではCore 2を圧倒するものの,4x128kB(※合計512kB)ではCore 2に逆転を許してしまう。ちょうど,L2キャッシュから外れるサイズが境になっている印象だ。64x128kB(=8MB)で再逆転するのは,Core 2だと6MBのL2キャッシュからあふれてしまうためであろう。
Multi-Core Efficiencyでは,128kBという,比較的小さなデータをコア間でやりとりするため,データはL2キャッシュとL3キャッシュ間の移動を繰り返すはず。それを踏まえるに,大きなメモリブロックにアクセスして転送レートを計るCache and Memoryとは異なり,ここではCPUコアから見たL3キャッシュのレイテンシがスコアに影響を与えている可能性を指摘できそうだ。それにしても,コア間データ転送の一部が外部バスを回するC2E QX9770に,Core i7が逆転されてしまうというのは……。
 |
とはいえ,L3キャッシュにパフォーマンス面のメリットがまったくなければ意味もないわけで,何らかの効果はあるはずだ。そこで,2007年12月25日の記事で使った筆者オリジナルのテストプログラムを,再び実行してみることにした。
このテストは,1〜4スレッドで同じメモリ領域へアクセスし,その速度を測るというもの。スレッド数に応じてオーバーヘッドが大きくなってアクセス速度は低下するが,共有キャッシュが有効に機能すれば,アクセス速度の低下度合いは小さくなるはずである。
ただし,Core i7はHyper-Threadingテクノロジーが有効で,OSからは8コアCPUに見えるため,スレッドを貼り付けるコアを変更し,1スレッド/1コアになるよう,コードに変更を加えている。Hyper-Threadingが有効な環境だと,同一コアで2スレッドが走るため,コア間のメモリ転送速度は高速に見えるのだが,今回のテストでそのようなことは起こらない。
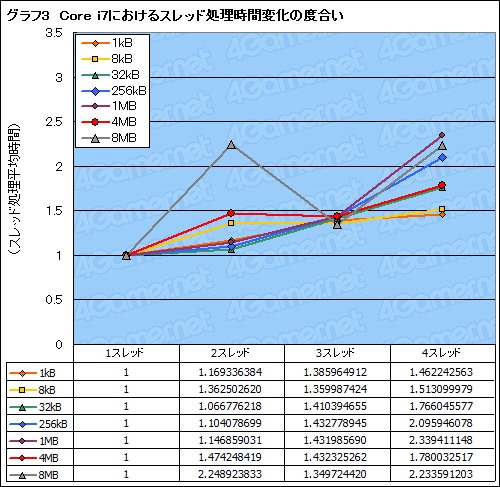
というわけで,1スレッド実行時の速度を1として,スレッド処理速度の相対的な増加率をCPUごとに示したのがグラフ3,4だ。
ここでは,アクセスメモリブロックサイズとして,1kBから8MBまで7パターン用意しているが,一見して傾向の違いは見て取れると思う。C2E QX9770ではコアをまたぐ3スレッド以上でスコアが一気に悪化するのに対し,Core i7では4スレッドでも2.5倍以内に収まっている。
8MBブロックのテスト時に,Core i7の2スレッドスコアが極端に悪化している理由は不明。8MBになると実データがL3キャッシュからはずれることがあるため,揺らぎが大きくなるのかもしれない。
一方,C2E QX9770では4MBのスコアが優秀に見えるが,ここでは,値が相対的なものである点に注意してほしい。C2E QX9770における4MBブロックの絶対的なスコアは非常に低く,そのため,スレッド間での差が出づらくなっているのだ。要するに,元々スコアが低いので,差が出ていないのである。
 |
 |
そして,それはもう少しミクロな視点でも確認できる。
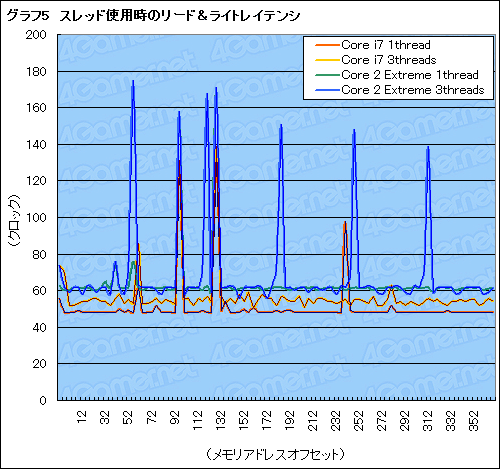
グラフ5は,やはり筆者オリジナルのツールを使ってメモリ領域に4bytes単位で順にアクセスしていき,その処理にかかるレイテンシを取り出したものだ。Core i7 965,C2E QX9770とも,1スレッド時(=別スレッドからの邪魔が入らない状態)と3スレッド時のスコアを取得している。
ここで注目したいのは,3スレッド同時実行時に,キャッシュ間(=コア間)転送が原因と思われるレイテンシの跳ね上がりが,C2E QX9770だと一定間隔で繰り返されるのに対して,Core i7だとその数が少ない点だ。
 |
グラフ3〜5から判断するに,数のスレッドで同じメモリ領域にアクセスするようなケースにおいて,L3キャッシュは(Core 2 Quad比で)確実に効いているといえる。
では,Multi-Core Efficiencyの結果は,なぜあのようになったのだろうか? これについては,後ほどあらためて考察しよう。
3chメモリコントローラの効果は?
Core i7の大きな特徴として挙げられるのが,CPUに統合されたトリプルチャネルメモリコントローラだ。Core i7は,シングル/デュアル/トリプルチャネルいずれの状態でも動作する,スケーラブルな仕様になっているが,果たしてその実力はどれほどのものだろうか。
Sandra 2009の「Memory Bandwidth」から,メモリバス帯域幅をチェックした結果がグラフ6である。C2E QX9770(+P45)をCore i7が圧倒しており,宣伝どおりのパフォーマンスを発揮できているといっていいだろう。
Core i7のデュアルチャネルアクセス時におけるスコアが,トリプルチャネル構成時と比べて75%のスコアを叩き出しているのは興味深い。単純計算なら3分の2となるはずなので,オーバーヘッドはまったくない。むしろ3chアクセス時のパフォーマンスがやや低めとすらいえるほどである。
 |
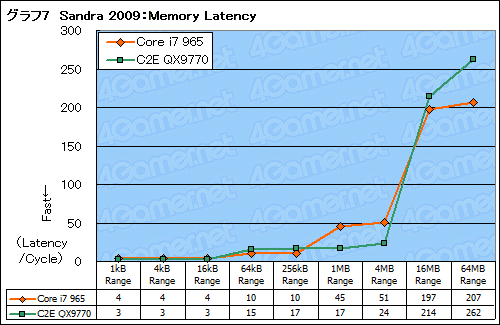
また,Athlon 64がそうだったように,メモリコントローラをCPUに統合すると,メインメモリへのアクセスにおけるレイテンシの低減も期待できる。Sandra 2009の「Memory Latency」テスト結果も見てみよう。
グラフ7では,Core i7 965のスコアが1MBと4MBでC2E QX9770を下回り,16MB以上で再逆転しているのが目を引く。1〜4MBというのは,Core i7だとL3キャッシュの範囲内,C2E QX9770だとL2キャッシュの範囲内なので,Core i7のL3キャッシュは,Core 2のL2キャッシュと比べてレイテンシが大きいことをあらためて確認できる。
一方,キャッシュを外れる範囲ではCore i7のレイテンシが低い。これはさすがの一言だ。
 |
ところで,テストのセットアップ時に,今回はサンマックステクノロジーズ製のPC3-10600モジュールをPC3-8500で利用すると述べたが,なぜそんなことをしたかというと,別途入手した,某大手ブランドのPC3-8500モジュール×3では,3回に1回程度の割合で,OSのログオンに失敗する問題があったためだ。Core i7が発売されれば,おそらく動作検証をパスした3chセットが続々と登場するだろうが,そういった製品を使わない場合は,スペックに余裕のあるモジュールを選択したほうがいいかもしれない。
なお,メモリレイテンシは今回7-7-7-18に詰めているが,SPDに書き込まれた9-9-9-24ならどうなるかを,念のためチェックしたのがグラフ8である。ご覧のとおり,16MB以上のレイテンシには確実に差が生じている。スペックに余裕のあるモジュールであれば,こういったレイテンシの低減にもチャレンジできることは,憶えておいて損はないだろう。
 |
CPU単体の性能は上がっているのか?
以上,キャッシュとメインメモリ周りを見てきたが,いずれもCore i7の“足回り”部分である。足回りはアプリケーション実効性能の向上に重要なポイントだが,では,CPUコアそのものは何がどう変わったのだろうか。ここからは,シンプルな演算性能だけに注目して,いくつかのテストを実行してみたい。
まずは,定番テストの一つである,Sandra 2009の「Processor Arithmetic」「Processor Multi-Media」のテスト結果からだ(グラフ9,10)。
Processor Arithmeticでは,整数演算の古典的なベンチマークである「Dhrystone」,浮動小数点演算ベンチマークの「Whetstone」がテストされるが,前者において,「Core i7 965ではSSEが使用されるのに対し,C2E QX9770ではALU(整数演算)が用いられる」点に注意してほしい。これは,Sandra 2009が「より速いほうを自動選択する」ためだが,異なる命令セットが使われているので,このスコアは比較には適さない。
そこで,SSE3の命令セットが用いられるWhetstoneから見ていくことになるが,ここではCore i7が順当に速くなっているように見える。また,同じくSSEが用いられているProcessor Multi-Mediaの結果も同様だ。なかでも,ゲームでも頻繁に用いられる「Float x4」演算のスコアにおける違いは大きい。
 |
 |
もっとも,Sandra 2009のテストはややざっくりしすぎている嫌いもある。もう少し細かく見るべく,Sandra 2009と同様に,システムの情報を表示したり,コンポーネントのベンチマークテストを行ったりできる「Everest」(Version 4.60)の結果も見ておきたい。
グラフ11において,テスト名が「CPU」で始まるモノは整数演算中心,「FPU」で始まるモノは浮動小数点演算中心である。いくつかピックアップして見ていきたいが,まずCPU PhotoWorxxはマルチスレッド化された整数演算による,画像処理の実行速度を測るテスト。マルチスレッド性能が表れやすい特徴を持つ。C2E QX9770に対してCore i7 965のスコアが65%も高いのは,L3キャッシュが効いている(=コア間のデータ転送にボトルネックが生じていない)可能性があるだろう。
CPU ZLibは圧縮ライブラリのテストで,メモリバス帯域幅がスコアを左右しやすい。したがって,Core i7がCore 2を圧倒するのは納得である。
一方,キャッシュ周りやメモリバス帯域幅がスコアを左右しづらいAES暗号化テストであるCPU AESだと,両者の差が非常に少なくなっている。CPUコアだけ比較すると,Core i7とCore 2の差はそう大きくないのかもしれない。
FPUではSinJuliaの差が大きい。SinJuliaは80bit浮動小数点数を用いてJuliaフラクタルの計算を行うもので,SSEではなくFPUを駆動するテストである。メインストリームのアプリケーションでは,FPUは徐々にSSEに取って代わられようとしているが,Core i7のFPU性能はかなりチューニングされているようだ。
 |
別記事でお伝えしているとおり,Core i7では,CPUの基本性能を向上させる要素として,改良版の「Loop Stream Detector」(以下,LSD)が実装されている。ゲームはもちろん,どんなプログラムでもループは多用されるため,LSDの改良は大きなメリットにつながっている可能性がある。
LSDは,Core 2だと18命令以内で,Core i7は28μOps以内のループで効くことになっている。ここで注意すべきは,「x86命令は1〜4個のμOpsに分解される」
点で,移動や加算,乗算など基本的な命令はx86命令とμOpsが1対1で対応しているのに対し,除算などは複数のμOpsに分解される可能性があること。そこで今回は,後者の利用を避けて28μOps=28命令となるようにしながら,ループの大きさを変えながらループ速度を計測するプログラムを作ってみたのだが,ここで意外な結果に出くわすことになった。
Core 2は18命令以内のループで,Core i7は28命令――厳密にいえば,Core i7は「28μOps」だが,μOpsとx86命令はほぼ1対1で対応するので,ここでは28命令とする――以内でLSDが効くことになっている。そこで,いくつかのサイズでループの速度を計測するプログラムを用意し,検証してみたのだが,ここで意外な結果に出くわすこととなった。
グラフ12は,12命令からなるループ(shortとする)と,22命令からなるループ(longとする)を用意し,これらループが2秒間に回る回数をカウントしたものだ。整数演算は「32bit長整数の掛け算と足し算を繰り返す」,SSEは「32bit単精度×4(Float x4)の掛け算,足し算を繰り返す」という単純なもので,どちらもL1キャッシュに収まってしまう。テストは「ループを回すスレッドを起動し,スタート後2秒経ったら別スレッドから打ち切る」という方法を選択している。
さて,グラフを見てみると分かるのだが,整数演算のテストを行う限り,C2E QX9770のほうが圧倒的に多くループが回ってしまうのである。これほどの差がついた理由は,執筆時点では分からないとしか言いようがない。ただ,shortとlongを総合的に見ると,Core i7のほうが長いループ命令を前にしたとき,スコアの落ち込みが少ないのは確かで,これこそが「LSDの効いている証」とは言えそうである。
また,SSE命令だとshortでCore i7 965がやや上回るものの,longではやはりC2E QX9770に逆転されてしまう。
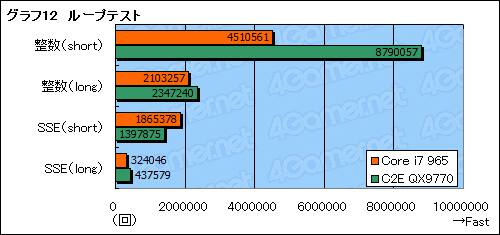 |
動作クロックを揃えて,まったく同一のプログラムを実行した状態でこの結果だと,Core i7が極端に苦手とする部分を突いてしまった可能性もある。この点については,もう少し情報を集めてから,あらためて検証してみる必要がありそうだ。
Core i7のキモはメモリコントローラと
キャッシュ構成?
ここまでのテストを終えた筆者の胸に去来するのは,「キャッシュに収まる範囲,換言すれば命令の実行エンジン部分において,Core i7とCore 2 Quadは,ほとんど変わっていないのではないか」という疑念である。グラフにはしていないが,ループテストでは,命令数を減らしていくと,Core i7のスコアがどんどん低くなっていく現象も見られており,少なくとも「実行エンジンがとてつもなく高速化した」雰囲気はない。
また,L3キャッシュも意外に(予想どおり?)レイテンシが大きそうである。これはPhenomでも似たような傾向があることから,L3キャッシュを持つCPUに共通するものかもしれない。
 |
4Gamerがテーマとするゲームでは,メモリバス帯域幅に加え,ミクロなベンチマークでは測定しづらいI/O周り……QPIのパフォーマンスが効いてくるだろう。ただし,Core 2の大容量L2キャッシュを頼みに設計されたゲームプログラムだと,L3キャッシュのレイテンシがマイナスに作用するケースも考えられる。
いずれにしても,Core 2が登場したときのように,手放しで「速い」と絶賛できるCPUとは言い切れない。これが,Core i7に対する筆者の現時点における見解である。
- 関連タイトル:
 Core i7(LGA1366,クアッドコア)
Core i7(LGA1366,クアッドコア) - この記事のURL:
(C)Intel Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー