










•À•Â°º•π
°ŒCOMPUTEX 2006°Ù11°œ∏˙≤à ™Õ˝•¢•Ø•ª•È•Ï°º•∑•Á•Û§œRadeon X1000§¨ÀÐÃø°©°°ATI°§°»Radeon 3ÀÁ∫π§∑Havok FX°…§ŒæÐ∫Ÿ§Ú∏¯≥´
 |
°°§Ω§¶°§§≥§Ï§œCOMPUTEX TAIPEI 2006§Œ•Ï•ð°º•»°Ù02§«§™≈¡§®§∑§∆§§§Î°§Intel¥ƒ¥π÷±È§«∏¯≥´§µ§Ï§ø°÷Havok FX°◊§Œ•«•‚•∑•π•∆•ý§¿°£
¢£§¢§È§ø§·§∆≥Œ«ß§π§ÎHavok FX§Œª≈¡»§þ
°°°÷Havok FX°◊§œ°§Havok§Œ ™Õ˝•∑•þ•Â•Ï°º•∑•Á•Û•þ•…•Î•¶•ß•¢°÷Havok 4 SDK°◊§À≈˝πÁ§µ§Ï§Î°÷∏˙≤à ™Õ˝° Effects Physics°À°◊§Œ•µ•÷•∑•π•∆•ý§«§¢§Î°ƒ°ƒ§»§§§¶§Œ§œ°§•Ï•ð°º•»§∑§ø§»§™§Í°£
°°§≥§ŒHavok FX§À§Ë§√§∆º¬∏Ω§µ§Ï§Î∏˙≤à ™Õ˝§Ú°§GeForce 6/7•∑•Í°º•∫§ŒGPU° •∞•È•’•£•√•Ø•π•¡•√•◊°À§«•¢•Ø•ª•È•Ï°º•»§π§Îª≈¡»§þ§œ°§GDC 2006§«NVIDIA§¨»Ø…Ω∫—§þ§¿°£∫£≤Û»Ø…Ω§µ§Ï§ø§Œ§œ§Ω§ŒATI»«§»§«§‚§§§¶§Ÿ§≠§‚§Œ§«°§Radeon X1000•∑•Í°º•∫§ÚÕ¯Õ—§∑§∆°§•¢•Ø•ª•È•Ï°º•∑•Á•Û§Ú𑧶°£
 |
°°§µ§∆°§§≥§Œπ‰¬Œ§Œæ◊∆Õ ™Õ˝§ŒΩËÕ˝§«…È≤Ÿ§¨§´§´§Î§Œ§œ°§≈–æϧπ§Îπ‰¬Œ∆±ªŒ§Œ¡Í∏þæ◊∆Õ»ΩƒÍ§»°§æ◊∆Õ∏§ŒµÛ∆∞§Œππø∑§¿°£
°°Havok FX§«§œ°§§≥§¶§∑§øΩËÕ˝§ÚGPU§Œ•‘•Ø•ª•Î•Ï•Û•¿•Í•Û•∞•—•§•◊•È•§•Û§ÀŒÆ§∑π˛§Û§«ΩËÕ˝§π§Î°£§µ§È§À∫Ÿ§´§Ø§§§®§–°§æ◊∆Õ§π§Î≤ƒ«Ω¿≠§Ú»Î§·§∆§§§Î•™•÷•∑•ß•Ø•»§Œ•⁄•¢§Ú∏´§ƒ§±§ÎΩËÕ˝§»°§æ◊∆ÕΩËÕ˝§Œ∑Î≤ð º°§À§…§Œ ˝∏˛§À∏˛§´§¶§´°§¬Æ≈Ÿ§‰≤√¬Æ≈Ÿ§œ§…§¶ —≤Ω§π§Î§´°À§Ú»ø±«§π§ÎΩËÕ˝§Ú°§•‘•Ø•ª•Î•Ï•Û•¿•Í•Û•∞•—•§•◊•È•§•Û§«º¬π‘§∑§∆§§§Î§Œ§¿°£
°°º¬∫𧌰÷≤ø§»≤ø§¨æ◊∆Õ§∑§ø§´°◊§»§§§¶»ΩƒÍ§»°§§Ω§Ï§À§Þ§ƒ§Ô§ÎΩËÕ˝∑œ§œHavok FX§À§™§§§∆§‚CPU§«ΩËÕ˝§µ§Ï§∆§§§Î°£GPU§«100°ÛΩËÕ˝§µ§Ï§Î§Ô§±§«§œ§ §§°£
°°§¡§ §þ§À°§§≥§Œ°÷CPU¬¶§À÷§µ§Ï§Î°◊§≥§»§œ…¨§∫§∑§‚•«•·•Í•√•»§–§´§Í§«§œ§ §§°£•≤°º•ýø π‘§À¥ÿ§Ô§Î°»ø∆°… ™Õ˝§»§‚§§§¶§Ÿ§≠ ™Õ˝ΩËÕ˝°÷•≤°º•ý•◊•Ï•§ ™Õ˝°◊° Game Play Physics°À§Ú≤∆˛§µ§ª§È§Ï§Î§≥§»§À§‚§ƒ§ §¨§Î°£
¢£°÷∏˙≤à ™Õ˝§Œ•¢•Ø•ª•È•Ï°º•∑•Á•Û§œRadeon X1000•∑•Í°º•∫§Œ§€§¶§¨GeForce§Ë§ÍÕ≠Õ¯°◊
°°§µ§∆°§ATI§Œ•Ì•∑•¢√¥≈ˆπ≠ Û§«°§ ™Õ˝•∑•þ•Â•Ï°º•∑•Á•Û§ÀæЧ∑§§Nick Radovskiy° •À•√•Ø°¶•È•…•’•π•≠°º°Àª·§œ°÷∏˙≤à ™Õ˝§Œ•¢•Ø•ª•È•Ï°º•∑•Á•Û§«§œ°§NVIDIA§ŒGeForce•∑•Í°º•∫§Ë§Í§‚Radeon X1000•∑•Í°º•∫§Œ§€§¶§¨Õ•§Ï§∆§§§Î°◊§»¿⁄§ÍΩ–§π§»§≥§Ì§´§È°§•◊•Ï•º•Û•∆°º•∑•Á•Û§Ú≥´ªœ§∑§ø°£
 |
°°§≥§ŒΩËÕ˝∑œ§À§™§§§∆°§≥∆•‘•Ø•ª•Î•∑•ß°º•¿•Ê•À•√•»§À¿Ï¬∞§Œ ¨¥Ù•Ê•À•√•»§Úº¬¡ı§π§ÎRadeon X1000•∑•Í°º•∫§Œ•¢°º•≠•∆•Ø•¡•„§œÕ≠Õ¯§À∆اا»°§Radovskiyª·§œ§§§¶°£
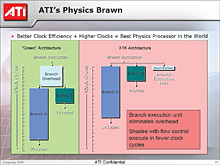 |
°°∂Ò¬Œ≈™§À¿‚ÿ§π§Î§»°÷æ◊∆Õ•π•Ï•√•…A°◊§Œ ¨¥Ù∑Î≤稰÷æ◊∆Õ∏§ŒΩËÕ˝°◊§Àø §þ°§°÷æ◊∆Õ•π•Ï•√•…B°◊§Œ ¨¥Ù∑Î≤稰÷æ◊∆Õ§∑§ §´§√§øæÏπÁ§ŒΩËÕ˝°◊§Àø §Û§¿§»§≠°§Radeon X1000•∑•Í°º•∫§«§œ ¬ŒÛº¬π‘§¨≤ƒ«Ω§ §Œ§¿°£§¡§ §þ§ÀRadeon X1000•∑•Í°º•∫§«§œ°§æ◊∆Õ•π•Ï•√•…§œ1•‘•Ø•ª•Î•∑•ß°º•¿•Ê•À•√•»≈ˆ§ø§Í16•π•Ï•√•…§ÚΩËÕ˝§π§Î°£§≥§Ï§œ§‚§¡§Ì§Û°§Radeon X1000•∑•Í°º•∫§Œ•‘•Ø•ª•Î•Ï•Û•¿•Í•Û•∞•—•§•◊•È•§•Û§¨4°þ4•‘•Ø•ª•Î§ŒΩËÕ˝§Ú§“§»§´§ø§Þ§Í§»§∑§∆§§§Î§≥§»§´§ÈÕ˧∆§§§Î°£§≥§Œ§¢§ø§Í§Œª≈¡»§þ§À§ƒ§§§∆§ŒæÐ∫Ÿ§œ°§…ƺ‘§Œœ¢∫Ч«Radeon X1800§‰Radeon X1900•∑•Í°º•∫§À§ƒ§§§∆≤Ú¿‚§∑§ø≤Û§Úª≤滧∑§∆§€§∑§§°£
°°§≥§Ï§À¬–§∑§∆°§GeForce 6/7•∑•Í°º•∫§Œ•‘•Ø•ª•Î•∑•ß°º•¿•Ê•À•√•»§À§œ¿Ï¬∞§Œ ¨¥Ù•Ê•À•√•»§¨§ §§§ø§·°§ ¨¥Ùª˛§À•Ï•§•∆•Û•∑§¨»Ø¿∏§π§Î°£§µ§È§À ¨¥Ù¿Ë§Œ∆±ª˛º¬π‘§‚§«§≠§ §§§Œ§«°§ ¨¥ÙΩËÕ˝ª˛§Œ•™°º•–°º•ÿ•√•…§¨¬Á§≠§Ø§ §Î§»§§§¶°£
°°§Þ§ø°§√±Ω„§À•»•√•◊•®•Û•…§«»Ê≥”§π§Ï§–°§GeForce 7900 GTX/GT§Œ•‘•Ø•ª•Î•∑•ß°º•¿•Ê•À•√•»§¨24¥§ §Œ§À¬–§∑°§Radeon X1900 XTX/XT§œ48¥§«§¢§Í°§√±Ω„§ øÙ§Œ»Ê≥”§«§‚Radeon X1000•∑•Í°º•∫§¨Õ≠Õ¯§»§Œ§≥§»§¿°£
¢£Radeon X1000•∑•Í°º•∫§Œ ™Õ˝•∑•þ•Â•Ï°º•∑•Á•ÛΩËÕ˝«ΩŒœ
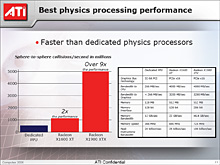 |
°°ATI§Œº¬∏≥§À§Ë§Ï§–°§√±∞ê˛¥÷§¢§ø§Í§À𑧮§ÎµÂæıæ◊∆Õ»ΩƒÍŒÃ§«»Ê≥”§π§Î§»°§Radeon X1600 XT§À§œ°§AGEIA Technologies¿Ω ™Õ˝±Èªª•¡•√•◊°÷PhysX PPU°◊§Œ2«Ð§ŒΩËÕ˝¿≠«Ω§¨§¢§Î§»»Ωÿ§∑§∆§§§Î§»§Œ§≥§»§¿°£Havok FX§œ∏˙≤à ™Õ˝§Œ•¢•Ø•ª•È•Ï°º•∑•Á•Û§¿§±§ §Œ§«°§•≤°º•ý•◊•Ï•§ ™Õ˝§Œ•¢•Ø•ª•È•Ï°º•∑•Á•Û§Þ§«§¨π‘§®§ÎPhysX PPU§¨ŒÙ§√§∆§§§Î§»§§§¶√ªÕÌ≈™§ »Ω√«§œ§«§≠§ §§§¨°§§≥§Œ•«°º•ø§ÚøƧ∏§Î§ §È°§∏˙≤à ™Õ˝§À¥ÿ§∑§∆§§§®§–°§Radeon X1600 XT§«…¨Õ◊ΩΩ ¨§ •—•’•©°º•Þ•Û•π§¨∆¿§È§Ï§Î§≥§»§À§ §Î°£
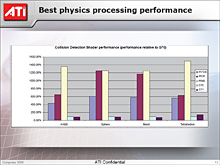 |
°°Radeon X1000•∑•Í°º•∫§¨∂ØŒœ§ ™Õ˝•∑•þ•Â•Ï°º•∑•Á•ÛΩËÕ˝«ΩŒœ§Úª˝§√§∆§§§Î§≥§»§Ú∆ߧާ®§∆°§•◊•È•§•Ÿ°º•»•÷°º•π§«Radeon X1000•∑•Í°º•∫§Ú3ÀÁ∫π§∑§ø•∑•π•∆•ý§Ú≈∏º®°§»‰œ™§∑§ø§»§§§¶§Ô§±§«§¢§Î°£
°°≈∏º®§µ§Ï§∆§§§ø•∑•π•∆•ý§œ°§2•—•ø°º•Û°£∞ϧƒ§œ°§Intel 975X Express•¡•√•◊•ª•√•»§Ú≈Î∫Ч∑°§PCI Express x16•π•Ì•√•»§Ú3ÀÐÕ—∞’§∑§øIntel¿Ω•Þ•∂°º•Ð°º•…°÷D975XBX°◊§ÚÕ¯Õ—§∑°§Radeon X1900 XT§Ú3ÀÁ∫π§∑° ¿µ≥Œ§À§œRadeon X1900 XT§¨2ÀÁ§»°§Radeon X1900 CrossFire Edition§¨1ÀÁ°À§∑§ø•∑•π•∆•ý§¿°£§≥§Œ•∑•π•∆•ý§«§œ°§2ÀÁ§¨CrossFire∆∞∫Ó§∑°§1ÀÁ§¨Havok FX§Œ∆∞∫Ó§À¿Ï«∞§π§Îª≈ÕÕ§À§ §√§∆§§§ø°£
°°§ø§¿§∑°§≥∆PCI Express x16•π•Ì•√•»§À≥‰§Í≈ˆ§∆§È§Ï§Î•Ï°º•ÛøÙ§À§œ¿©∏¬§¨§¢§Í°§§≥§Œ•«•‚§À§™§§§∆§œ°§CrossFire§Œ2ÀÁ§¨≥∆8•Ï°º•Û°§Havok FX¿Ï«§§Œ1ÀÁ§œ4•Ï°º•Û¿Ð¬≥§À§ §√§∆§§§Î§»§§§¶°£
°°§‚§¶∞ϧƒ§œ°÷∏˙≤à ™Õ˝§Œ•¢•Ø•ª•È•Ï°º•∑•Á•Û§ §È…¨Õ◊ΩΩ ¨°◊§»§µ§Ï§ø°§Radeon X1600 XT§ÚÕ¯Õ—§∑§ø•«•‚§¿°£
°°§≥§¡§È§œ°§Intel¿ΩCPUÕ—•¡•√•◊•ª•√•»§»§ §Î°§Ã§»Ø…Ω§Œ•¡•√•◊•ª•√•»°÷RD600°◊° ≥´»Ø•≥°º•…•Õ°º•ý°À•Ÿ°º•π§Œ•Þ•∂°º•Ð°º•…§Úª»Õ—°£§§§∫§Ï§‚16•Ï°º•Û§«∆∞∫Ó§π§Î°§2ÀЧŒPCI Express x16•π•Ì•√•»§ÀRadeon X1900 CrossFire Edition§»Radeon X1900 XT•´°º•…§Ú∫π§∑§∆CrossFire∆∞∫Ó§µ§ª°§2ÀÁ§Œ¥÷§À§¢§ÎPCI Express x1•π•Ì•√•»§À°§Radeon X1600 XT§Ú∫π§π§»§§§¶πΩ¿Æ§¿°£Radeon X1600 XT§œ°§x1¢™x16§Œ•π•Ì•√•» —¥π•¢•¿•◊•ø§Ú∂¥§þπ˛§Û§«°§»æ§–∂Ø∞˙§À∫π§∑§∆§§§Î°£
°°•π•Ì•√•»…˝§ÚPCI Express x16§À§∑§ø§»§≥§Ì§«°§≈¡¡˜§œ1•Ï°º•Û§«π‘§Ô§Ï§Î§ø§·°§¡«ƒæ§ÀPCI Express x1ª≈ÕÕ§ŒRadeon X1600 XT•´°º•…§Ú∫π§π§€§¶§¨•π•Þ°º•»§¿§¨°§§Ω§¶§§§√§ø•«•∂•§•Û§Œ•´°º•…§¨§ §§§ø§·°§§≥§Œ§Ë§¶§ ∑¡§Œ•«•‚§À§ §√§ø§Œ§¿§»§§§¶°£Radovskiyª·§§§Ô§Ø°§°÷ —¥π•¢•¿•◊•ø§Úº¬∫ð§À»Ø«‰§π§Î∑◊≤˧œ§ §§°◊§»§Œ§≥§»§«°÷§¢§Ø§Þ§«•≥•Û•ª•◊•»§Œ≈∏º®°◊§»§§§¶§≥§»§È§∑§§°£
 |
 |
 |
°°§¡§ §þ§À∆±ª·§œ°§2∏ƒ§ŒGPU§«•∞•È•’•£•√•Ø•π•Ï•Û•¿•Í•Û•∞°§1∏ƒ§ŒGPU§« ™Õ˝•¢•Ø•ª•È•Ï°º•∑•Á•Û§Ú𑧶•∑•π•∆•ý§Ú°÷2°Ð1°◊°§1∏ƒ§ŒGPU§«•∞•È•’•£•√•Ø•π°§1∏ƒ§ŒGPU§« ™Õ˝§Úπ‘§Ô§ª§Î•∑•π•∆•ý§Ú°÷1°Ð1°◊§»…Ω∏Ω°£§≥§Œ§Ë§¶§À°§GPU§À∞€§ §Îª≈ªˆ§Úπ‘§Ô§ª§Î•∑•π•∆•ý§Ú°÷»Û¬–挕≥•Û•’•£•∞•Ï°º•∑•Á•Û° Asymmetrical Configurations°À°◊§»∏∆挧∑§ø°£
°°§ §™°§1°Ð1§œ§»§‚§´§Ø°§2°Ð1•∑•π•∆•ý§À¥ÿ§∑§∆§œ°§§…§Œ§Ë§¶§ ∑¡§«•Ê°º•∂°º§ÀƒÛ∂°§π§Î§´§Œ ˝øÀ§œ§Þ§√§ø§Ø∑˧ާ√§∆§§§ §§§»§Œ§≥§»°£∏Ωª˛≈¿§«2°Ð1§Œ3ÀÁ∫π§∑•∑•π•∆•ý§œ°§•‚°º•ø°º•∑•Á•¶§«§§§¶§»§≥§Ì§Œ°÷•≥•Û•ª•◊•»•´°º≈∏º®°◊§»§§§¶∞Ã√÷§≈§±§»¬™§®§ø§€§¶§¨§§§§§¿§Ì§¶°£
 |
 |
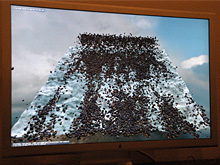
°°Radovskiyª·§œ•◊•Ï•º•Û•∆°º•∑•Á•Û§Œ∫«∏§À°§º¬∫ð§ÀRadeon X1900 XT§Œ2°Ð1•∑•π•∆•ý§ÚÕ¯Õ—§∑§∆°§Havok FX§Œ•¢•Ø•ª•È•Ï°º•∑•Á•Û¿≠«Ω§Ú»‰œ™§∑§ø°£
°°•«•‚§œ15000∏ƒ§Œ¥‰§Úº–Ãç´§È≈槨§π§»§§§¶§‚§Œ§«°§Core 2 Duo E6700/2.66GHz§À§Ë§Î•Ω•’•»•¶•ß•¢ΩËÕ˝§¿§» ø∂—•’•Ï°º•ý•Ï°º•»§¨6°¡7fps§ÀŒ±§Þ§Î§Œ§À¬–§∑°§§≥§Œ2°Ð1•∑•π•∆•ý§«§œ°§60°¡70fps§Ú•Þ°º•Ø§∑§∆§§§ø°£
 |
 |
¢£º°§ §Î•π•∆•√•◊§œ•≤°º•ý•◊•Ï•§ ™Õ˝§Œ•¢•Ø•ª•È•Ï°º•∑•Á•Û§´
 |
°°§‰§œ§Í°§•≤°º•ý§Œø π‘§Úª §Î§Œ§œCPU§Œª≈ªˆ§«§¢§Í°§§Ω§≥§Þ§«§œGPU§¨≤∆˛§«§≠§Î§‚§Œ§«§œ§ §§§´§È§¿°£
°°º°§ §Î•∆°º•Þ§œ§‰§œ§Í°§•≤°º•ýø 𑧉•≤°º•ý•Ì•∏•√•Ø§À¥ÿ§Ô§Î ™Õ˝•∑•þ•Â•Ï°º•∑•Á•Û§«§¢§Î°÷•≤°º•ý•◊•Ï•§ ™Õ˝°◊§Ú°§GPU§«•¢•Ø•ª•È•Ï°º•∑•Á•Û§π§Î•—•È•¿•§•ý§«§œ§ §§§¿§Ì§¶§´°£
°°§≥§Œ≈¿§À§ƒ§§§∆°§Radovskiyª·§œ°§§¢§Ø§Þ§«∏ƒøÕ≈™§ ∞’∏´§«§¢§Î§»√«§√§ø§¶§®§«°§º°§Œ§Ë§¶§ÀΩ“§Ÿ§Î°£
°°°÷•≤°º•ý•◊•Ï•§ ™Õ˝§ÚGPU§«•¢•Ø•ª•È•Ï°º•∑•Á•Û§π§Î§≥§»§œΩΩ ¨≤ƒ«Ω§¿°£§∑§´§∑°§§Ω§¶§ §Î§»°§•≤°º•ý¿þ∑◊§¨GPU¿≠«Ω§À∞Õ¬∏§∑§∆§∑§Þ§§°§•≤°º•ý§Œ¿þ∑◊§Ω§Œ§‚§Œ§¨∆Ò§∑§Ø§ §Î°£§Ω§Œ§ø§·°§•≤°º•ý§Œ≥´»Øº‘§œ§Ω§¶§∑§øµªΩ—§Ú≥ËÕ—§π§Î§Œ§À§¢§Þ§Í¿—∂À≈™§À§ §È§ §§§»ª◊§¶°◊
°°∏Ω∫þ§ŒHavok FX§‚ATIÕ—§»GeForceÕ—§À§œ Õ–•§• •Í§¨…¨Õ◊§«§¢§Í°§GPU§Œ¿≠«Ω§¨•œ•§•®•Û•…§»•–•Í•Â°º•Ø•È•π§»§«∞€§ §Î§≥§»§Þ§«πÕ§®§Î§»°§≥Œ§´§À•≤°º•ýø π‘§Àõ¥ÿ∑∏§ ∏˙≤à ™Õ˝§œ•π•±°º•È•”•Í•∆•£§ŒÃ竺¬¡ı§¨¥ √±§¿°£¿≠«Ω§Œƒ„§§GPU§ÚÕ¯Õ—§π§Î§»§≠§œ°§§Ω§Ï§≥§Ω°»≥‰§Ï§ø¥‰§Œ«À “°…§Úæا §Ø§π§Ï§–§§§§§¿§±§¿§∑°§§Ω§Œ«À “§œª∂§È§–§Î§¿§±§«•≤°º•ýø π‘§À§œ≤ø§Œ±∆∂¡§‚µ⁄§Ð§µ§ §§°£
°°§»§≥§Ì§¨°§•≤°º•ý•◊•Ï•§ ™Õ˝§ŒæÏπÁ°§≈–æϧπ§Î≈®§‰æ„≥≤ ™§ŒøÙ§¨∞€§ §Ï§–°§•≤°º•ý§Œ•Î°º•Î¿þƒÍ§‰•–•È•Û•πÃ猿þ∑◊§Þ§«§‚•π•±°º•È•÷•Î§À§π§Î…¨Õ◊§¨§¢§Î°£§≥§Ï§œ°§¥ √±§ §≥§»§«§œ§ §§°£
°°§»§œ§§§®°§°÷•≤°º•ý•◊•Ï•§ ™Õ˝§‚±Èªª¿∫≈Ÿ§‰±Èªª…—≈Ÿ§Œ¬¶Ãç«•π•±°º•È•”•Í•∆•£§Ú¿þ§±§Ï§–°§§¢§Îƒ¯≈Ÿ§œ¬–±˛§«§≠§Î°◊§»∏¿§Ô§Ï§∆§§§Î°£Œ„§®§–°§π‚¿≠«Ω§ CPU§Ú≈Î∫Чπ§Î•∑•π•∆•ý§À§™§§§∆§œ°§ ™Õ˝•∑•þ•Â•Ï°º•∑•Á•Û§Œ±Èªª…—≈Ÿ§ÚÀË•’•Ï°º•ý𑧶§¨°§§Ω§¶§«§ §§CPU§«§œøÙ•’•Ï°º•ý§¥§»§À𑧧°§¥÷§Ú¿˛∑¡ ‰¥÷§«§ƒ§ §∞§»§§§¶º¬¡ı§Úπ‘§√§∆§§§Î•≤°º•ý•ø•§•»•Î§‚°§∏Ωª˛≈¿§«§π§«§À¬∏∫þ§π§Î°£
°°WinHEC 2006§Œ•Ï•ð°º•»§«Ω“§Ÿ§ø§Ë§¶§À°§Windows Vista°ÐDirectX 10.1¿§¬Â§«§œ°§GPU§¨¥∞¡¥§À≤æ¡€≤Ω§µ§Ï§∆°§•∑•π•∆•ý§´§È°»º´Õ≥§Àª»§®§Î•≥•◊•Ì•ª•√•µ° CPU§Œ ‰Ωı§Ú§π§Î•◊•Ì•ª•√•µ°À°…§»§∑§∆∏´§®§Î§Ë§¶§À§ §Î°£§≥§Œª˛¬Â§À§ §Ï§–°§§Ω§¶§∑§øº¬¡ı§œ§Ë§Íº¬∏Ω§µ§Ï§‰§π§Ø§ §Î§¿§Ì§¶°£
°°GPU§» ™Õ˝±Èªª§Œ¥ÿ∑∏§œ§Þ§¿ªœ§Þ§√§ø§–§´§Í°£∫£∏§Œ∆∞∏˛§À√ÌÃЧ∑§∆§§§≠§ø§§°£° •»•È•§•º•√•» ¿æ¿Ó¡±ª °À
- ¥ÿœ¢•ø•§•»•Î°ß
 ATI Radeon X1900
ATI Radeon X1900
- ¥ÿœ¢•ø•§•»•Î°ßATI Radeon X1600
- ¥ÿœ¢•ø•§•»•Î°ßHavok
- §≥§Œµ≠ªˆ§ŒURL°ß
•≠°º•Ô°º•…
- •À•Â°º•π
- HARDWARE
- GPU
- Radeon
- •§•Ÿ•Û•»
- COMPUTEX TAIPEI 2006
- COMPUTEX TAIPEI
- AMD
- •È•§•ø°º:¿æ¿Ó¡±ª
- HARDWARE:Havok
- Havok.com
° C°À2006 Advanced Micro Devices Inc.
° C°À2006 Advanced Micro Devices Inc.
° C°ÀCopyright 1999-2008 Havok.com Inc (or its licensors). All Rights Reserved.
4Gamer.net∫«ø∑æ Û
•◊•È•√•»•’•©°º•ý Ãø∑√µ≠ªˆ
¡ÌπÁø∑√µ≠ªˆ
¥Î≤˵≠ªˆ
ø∑√Âœ¢∫Ð
ø∑√•ϕ”•Â°º
ø∑√•§•Û•ø•”•Â°º